
Das Bundesdatenschutzgesetz fordert die Anonymisierung und Pseudonymisierung von personenbezogenen Daten. Was sich hinter den beiden Begriffen verbirgt und wie Sie die gesetzlichen Anforderungen erfüllen, erläutert dieser Artikel.
Update: HIPAA Forderungen berücksichtigt
Anonymisierung und Pseudonymisierung: Was ist das?
Begriffsdefinitionen
Die Definition des Begriffs Anonymisierung fand sich am alten Bundesdatenschutzgesetz (Jahr 1990).
„Anonymisieren ist das Verändern personenbezogener Daten derart, dass die Einzelangaben über persönliche oder sachliche Verhältnisse nicht mehr oder nur mit einem unverhältnismäßig großen Aufwand an Zeit, Kosten und Arbeitskraft einer bestimmten oder bestimmbaren natürlichen Person zugeordnet werden können.“
Quelle: BDSG
Den Begriff „Pseudonymisieren“ definiert die europäische Datenschutzgrundverordnung DSGVO gleichlautend mit dem neuen Bundesdatenschutzgesetz (2018):
„„Pseudonymisierung“ die Verarbeitung personenbezogener Daten in einer Weise, dass die personenbezogenen Daten ohne Hinzuziehung zusätzlicher Informationen nicht mehr einer spezifischen betroffenen Person zugeordnet werden können, sofern diese zusätzlichen Informationen gesondert aufbewahrt werden und technischen und organisatorischen Maßnahmen unterliegen, die gewährleisten, dass die personenbezogenen Daten nicht einer identifizierten oder identifizierbaren natürlichen Person zugewiesen werden;“
Quelle: DSGVO Artikel 4(5)
Beide Verfahren haben das Ziel, den Datenschutz von Personen bzw. Patienten zu gewährleisten.
Pseudonymisierung
Dazu ersetzt man bei der Pseudonymisierung die Daten, die eine Identifikation erlauben würde, mit einem Pseudonym, beispielsweise einem Code. Es existiert jedoch eine getrennte Zuordnung (z. B. in Form einer Tabelle) zwischen dem Subjekt und dem Pseudonym, so dass es letztlich noch möglich ist, das Subjekt wieder zu identifizieren, wenn man diese Zuordnung kennt.
In Krankenhäusern nutzt man das gelegentlich, um VIPs zu schützen. Bei klinischen Versuchen arbeiten die Auswertenden ebenfalls häufig mit pseudonymisierten Daten. Besteht ein wichtiger Grund, das ursprüngliche Subjekt (den Patienten) zu identifizieren, so ist dies möglich.
Bei vielen Webanwendungen, bei denen man einen Benutzernamen frei wählen kann, der dann anderen Anwendern der gleichen Plattform angezeigt wird, haben wir es auch mit Pseudonymisierung zu tun, weil der Betreiber der Plattform die Zuordnung zwischen Person und Pseudonym kennt.
Anonymisierung
Bei der Anonymisierung hingegen werden alle identifizierenden Merkmale gelöscht. Das ist wie bei der Pseudonymisierung jedoch nicht trivial, im Fall von Gendaten sogar unmöglich.

Ansätze zur Anonymisierung und Pseudonymisierung
Sowohl bei der Anonymisierung als auch bei der Pseudonymisierung müssen identifizierende Merkmale so gelöscht (bei Anonymisierung) oder von den anderen personenbezogenen Daten getrennt (bei Pseudonymisierung) getrennt werden, dass ein Rückschluss auf die Person bzw. deren schutzwürdige Daten wesentlich erschwert wird.
Hierzu genügt es in der Regel nicht, nur die Merkmale zu entfernen, die relativ direkt auf die Person rückschließen lassen.
Beispiele
Beispiele dafür wären der Name, der genaue Wohnort, die E-Mail, Telefonnnummer oder das Geburtsdatum.
Meist ist es zusätzlich erforderlich, Daten zu verfälschen, zu verändern oder zu gruppieren:
- Wohnort (inklusive Straße und Hausnummer) durch Postleitzahl oder sogar nur erste Ziffern der Postleitzahl ersetzen
- Geburtsdatum auf Jahreszahl oder sogar größeres Intervall (z. B. fünf Jahre) limitieren
- Bei hierarchischen Kodiersystemen (Taxonomien wie der ICD-Diagnosekatalog) Werte auf höhere Hierarchieebene reduzieren
- Einzelwerte zu kombiniertem Wert zusammenfassen. Beispielsweise könnte man Leberwerte wie Gamma-GT, GOT oder GPT zusammenfassen in „erhöhte Leberwerte“ und „unauffällige Leberwerte“
- Zeitliche und räumliche Bezüge entfernen oder abstrakter gestalten. Beispielsweise konnten bei einer vermeintlich anonymisierten Datensammlung Personen identifiziert werden, weil es nur wenige Menschen gab, die zu bestimmten Zeitpunkten von einem zum anderen Ort umzogen
- Werte oder Datensätze entfernen
Mit Hilfe der k-Anonymität gelingt es, den Grad der Anonymisierung bzw. Pseudonymisierung zu bewerten. Die folgende Präsentation behandelt die Problematik der De-Anonymisierung und stellt das Konzept der k-Anonymität vor.
Sie sehen gerade einen Platzhalterinhalt von Standard. Um auf den eigentlichen Inhalt zuzugreifen, klicken Sie auf den Button unten. Bitte beachten Sie, dass dabei Daten an Drittanbieter weitergegeben werden.
Weitere InformationenWertvolle Hinweise zum Thema Anonymisierung als auch zu Verfahren liefert der Leitfaden des BDI zur Anonymisierung personenbezogener Daten.
Herausforderungen
- Interessenskonflikte
Meistens stehen sich der Anspruch auf informationelle Selbstbestimmung und das Interesse an der Datenauswertung (z. B. in der Forschung) konkurrierend gegenüber. - Unzureichende Pseudonymisierung
Daten in Form eines Diagnose-Codes und einer Postleitzahl, die über eine pseudonymsierte Patienten-ID verknüpft sind, betrachtet man in der Regel als ausreichend pseudonymsiert. Wenn die PLZ jedoch ein 2000-Einwohnerdorf repräsentiert und die Diagnose ausreichend selten ist (z. B. Down-Syndrom), kann die Zuordnung gelingen. - De-Anonymisierung mit Hilfe weiterer Daten
Regelmäßig übersieht man die Tatsache, dass es neben den eigenen pseudonymisierten Daten weitere Daten gibt, die in Kombination mit den eigenen Daten eine De-Anonymisierung erleichtern. Hier sind insbesondere öffentliche Daten wie solche aus sozialen Netzwerken zu betrachten. Es gibt mehrere Beispiele, in denen die De-Anonymisierung gelang [1, 2, 3].
Die US-Regierung nennt folgendes Beispiel:
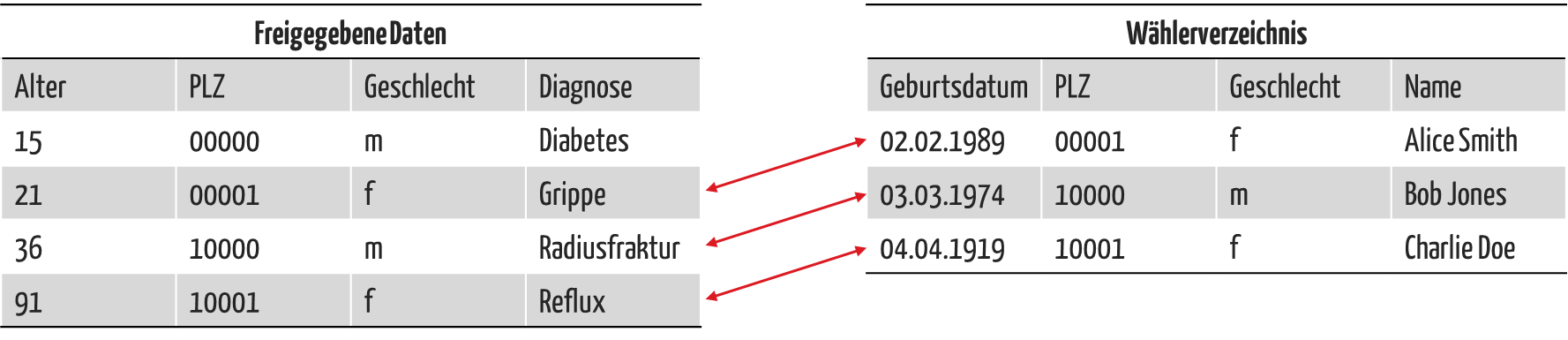
Durch die Kombination von pseudonymisierten oder gar anonymisierten Daten (Abb. 2, links) mit anderen Datenquellen wie hier einem Wählerverzeichnis (Abb. 2, rechts), lassen sich Rückschlüsse auf einzelne Personen ziehen. Im obigen Beispiel gelang das nur im ersten Fall nicht, weil die Person zu jung und damit nicht im Wählerverzeichnis registriert war.
Risikomanagement
Das Risiko eine Identifizierung wächst, durch
- das Kombinieren geeigneter Datenquellen,
- Attribute eines Datensatzes, die es alleine oder in Kombination mit anderen Attributen dieses Datensatzes erlauben, kleine Patientengruppen oder bereits einzelne Patienten zu charakterisieren,
- Datenquellen, die öffentlich verfügbar (aber nicht notwendigerweise jedem bekannt) sind, wie beispielsweise Wählerverzeichnisse,
- Attribute, die nicht veränderlich sind wie Geburtsdatum und Geschlecht (Wohnort kann sich leichter ändern).
Beachten Sie, dass Sie ein systematisches Risikomanagement betreiben und dafür auf Experten wie Statistiker zurückgreifen müssen.
Die Maßnahmen zur Risikominimierung finden Sie weiter oben beschrieben.
Regulatorische Anforderungen
Datenvermeidung und Datensparsamkeit
Das DSGVO fordert in Artikel 32:
„Unter Berücksichtigung des Stands der Technik […] treffen der Verantwortliche und der Auftragsverarbeiter geeignete technische und organisatorische Maßnahmen, um ein dem Risiko angemessenes Schutzniveau zu gewährleisten; diese Maßnahmen schließen unter anderem Folgendes ein:
die Pseudonymisierung und Verschlüsselung personenbezogener Daten;“
Zulässigkeit der Datenerhebung, -verarbeitung und -nutzung
Generell ist es laut BDSGs generell nicht erlaubt, personenbezogene Daten zu speichern, zu verarbeiten und zu nutzen. Allerdings gibt es von diesem umfassenden Verbot Ausnahmen:
- Eine Rechtsvorschrift erlaubt oder fordert dies
- Der Betroffene hat eingewilligt
Anforderungen des HIPAA
Der U.S. Health Insurance Portability and Accountability Act, kurz HIPAA, regelt auch die Anforderungen an die Vertraulichkeit von Gesundheitsdaten. Das US Gesundheitsministerium hat auf seiner Webseite Informationen zur Anonymisierung und Pseudonymisierung zusammengetragen.
Der HIPAA sieht zwei Möglichkeiten vor, um Daten ausreichend zu pseudonymisieren:
- Alle 18 Attribute eines Datensatzen werden gelöscht und man sieht auch sonst keine Möglichkeiten, die Daten wieder zuzuordnen.
- Experten bestimmen, welche Informationen gelöscht oder verändert werden müssen, um das Risiko einer Identifizierung einer Person zu minimieren.
Der Umgang mit den 18 Attributen ist allerdings teilweise US-spezifisch und muss teilweise auf europäische Verhältnisse angepasst werden:
- Namen der Person
- Geographische Unterteilungen, die kleiner als ein Staat sind. ZIP-Codes müssen so verändert werden (z. B. durch Ändern der letzten Ziffern auf 0), dass keine Gruppe weniger als 20.000 Personen umfasst.
- Alle Datumsinformationen (bis auf das Jahr), die sich auf ein Individuum beziehen wie z. B. Aufnahmedatum oder Geburtsdatum. Zusätzlich dürfen Personen, die über 89 sind, nicht verwendet werden, es sei denn man fasst alle Patienten zur Gruppe der Überneunzigjährigen zusammen.
- Telefonnummern
- Informationen zum Identifizieren von Fahrzeugen wie Kennzeichen oder Seriennummern
- Faxnummern
- Informationen zum Identifizieren von Medizingeräten wie Seriennummern.
- E-Mailadressen
- URLs
- Social Security Nummern
- IP-Adressen
- Nummern von Krankenakten bzw. Fallnummern
- Biometrische identifizierende Merkmale wie Fingerabdrücke
- Krankenkassennummern
- Fotos des gesamten Gesichts
- Kontonummern
- Jede eindeutige und identifizierende Nummer
- Nummern von Zertifikaten und Lizenzen (z. B. Heilberufeausweis)
Lesen Sie hier mehr zum Thema Datenschutz im Gesundheitswesen.
Änderungshistorie
- 2020-11: Link zu Leitfaden des BDI eingefügt

Gendaten sind das eine Problem bei der Anonymisierung, wobei derjenige, der die Anonymität des Patienten aufheben wollte dazu eine zweite Genanalyse die NICHT anonymisiert wurde benötigt.
Im Zusammenhang mit 3D-Rekonstruktionen von Schnittbildern des Schädels, inkl. Surface Rendering könnte man die Ergebnisse sogar über die Google Gesichtserkennung evt. wieder Rr-Anonymisieren. Aber das halte ich für sehr akademisch….
Realitätsnäher sind da schon zwei andere Aspekte:
1.) Manche Modalitätenhersteller speichern Patienteninformationen in „Private Tags“, wo sie oft bei der Anonymisierung bzw. Pseudonymisierung übersehen werden
2.) In vielen Arztbriefen finden wir Hinweise auf den Patienten im Fließtext (also Body um im CDA Kontext zu sprechen) wo sie nicht hingehören…
Auch wenn die TMF uns schon gute und brauchbare Möglichkeiten bietet softwareseitig das richtige zu tun, bleibt noch viel Arbeit zu leisten
Vielen Dank für diesen informativen Artikel!
Und es ist doch auch ernüchternd, dass das alte HIPAA-Gesetz der DSGVO in diesem Punkt deutlich voraus ist, weil es konkrete Vorgaben macht, wie eine richtige Anonymisierung aussieht, anstatt durch unklare Definitionen viele Fragezeichen zu hinterlassen. Ein Artikel zur Kategorisierung verschlüsselter Daten in die drei Bereiche wäre auch super!
Wie verhält es sich denn mit einem durch eine Hashfunktion generierten Pseudonym? Sodass zwar jederzeit „Herr Schmidt“ durch „392B“ ersetzt werden kann, aber eben keine Zuordnungstabelle existiert und somit „392B“ nie auf Herrn Schmidt zurückgeführt werden kann?
Sind die Daten in diesem Fall anonymisiert und gar nicht mehr pseudonymisiert?
(Anm: Das würde natürlich erfordern, dass der Hash so konstruiert wird, dass man nicht durch „Ausprobieren“ das Pseudonym erraten kann, also schon komplizierter als nur aus Name + Geburtsdatum abgeleitet.)
Sehr geehrter Herr Spohn,
die Generierung von Pseudonymen durch asymmetrischen Funktionen ist absolut denkbar. Sie sind aber nicht zwingend.
Ob durch eine Hash-Funktion bereits eine Anonymisierung erreicht ist, hängt davon ab, wie hoch der Aufwand wäre, um auf die Person zurückzuschließen. Mit einem „gesalten“ Hash sollte das möglich sein.
Besten Dank für Ihre wertvollen Gedanken!
Viele Grüße, Christian Johner