
Immer mehr Medizinprodukte nutzen künstliche Intelligenz, um Krankheitsbilder präziser zu diagnostizieren und Patienten wirksamer zu behandeln.
Bitte beachten Sie den Übersichtsartikel mit den Definitionen der Begriffe „künstliche Intelligenz“, „Machine Learning“ und „Neuronale Netzwerke“.
Unser Auditgarant bietet eine umfangreiche Unterstützung mit mehr als 25 Videotrainings zur KI sowie passenden Templates.
1. Anwendungen der künstlichen Intelligenz in der Medizin
a) Übersicht
Hersteller nutzen künstliche Intelligenz, insbesondere Machine Learning, für Aufgabenstellungen wie die folgenden:
| Aufgabenstellung | Daten, mit denen KI diese Aufgabe unterstützen kann |
| Detektion einer Retinopathie | Bilder des Augenhintergrunds |
| Zählen und Erkennen bestimmter Zelltypen | Bilder von histologischen Schnitten |
| Diagnose von Infarkten, Alzheimer, Krebs usw. | Radiologische Bilder, z. B. CT, MRT |
| Erkennung von Depression | Sprache, Bewegungsmuster |
| Auswahl und Dosierung von Medikamenten | Diagnosen, Gen-Daten usw. |
| Diagnose von Herzerkrankungen, degenerative Erkrankungen des Gehirns usw. | EKG- oder EEG-Signale |
| Erkennen von Epidemien | Internet-Suchen |
| Prognose von Krankheiten | Laborwerte, Umweltfaktoren usw. |
| Prognose des Todeszeitpunkts von Intensivpatienten | Vitalparameter, Laborwerte und weitere Daten in der Patientenakte |
Zu den weiteren Anwendungsgebieten zählen:
- Erkennung, Analyse und Verbesserung von Signalen, z. B. schwachen und verrauschten Signalen
- Extraktion strukturierter Daten aus unstrukturiertem Text
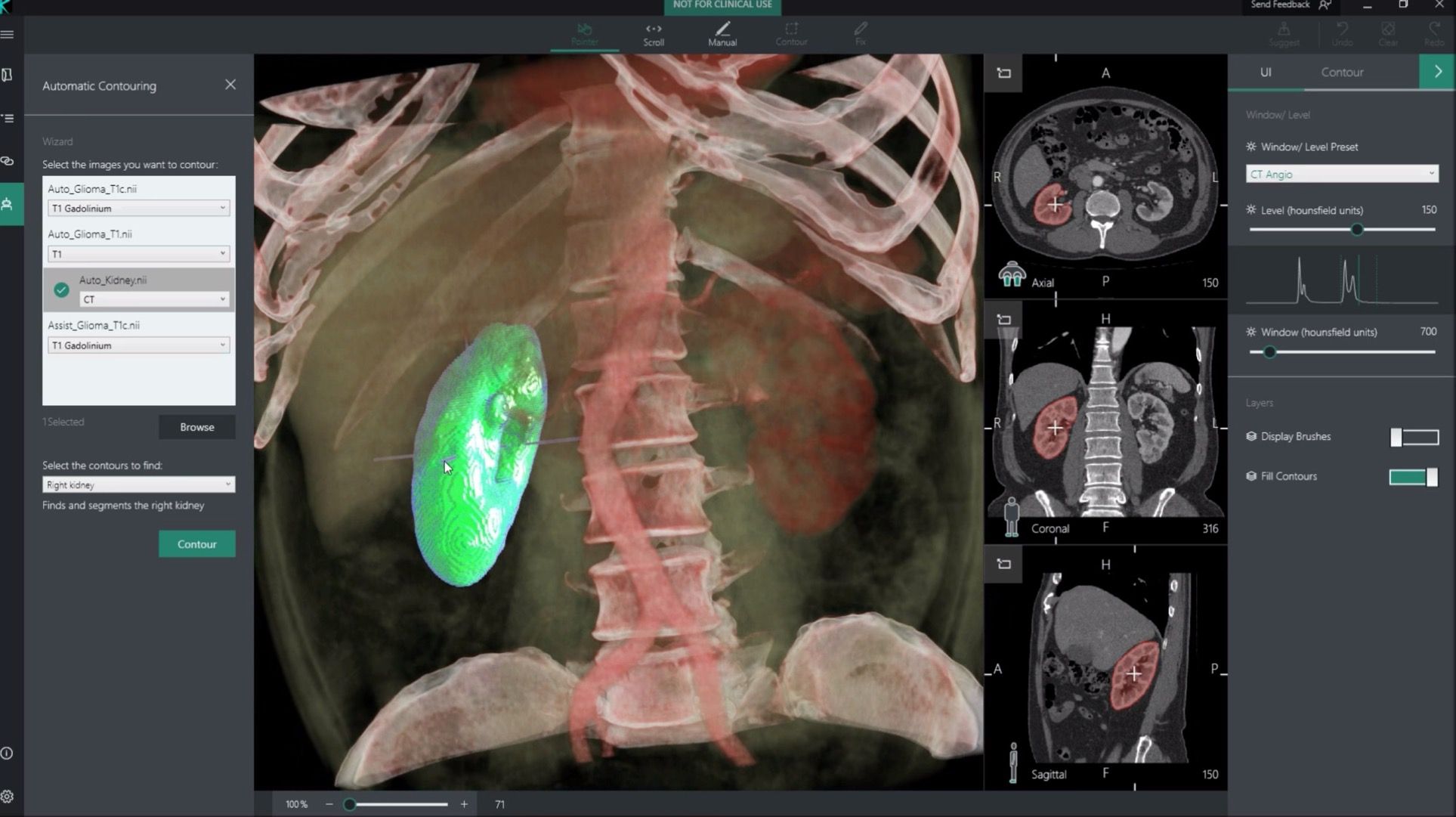
- Segmentierung von Geweben, z. B. für die Bestrahlungsplanung
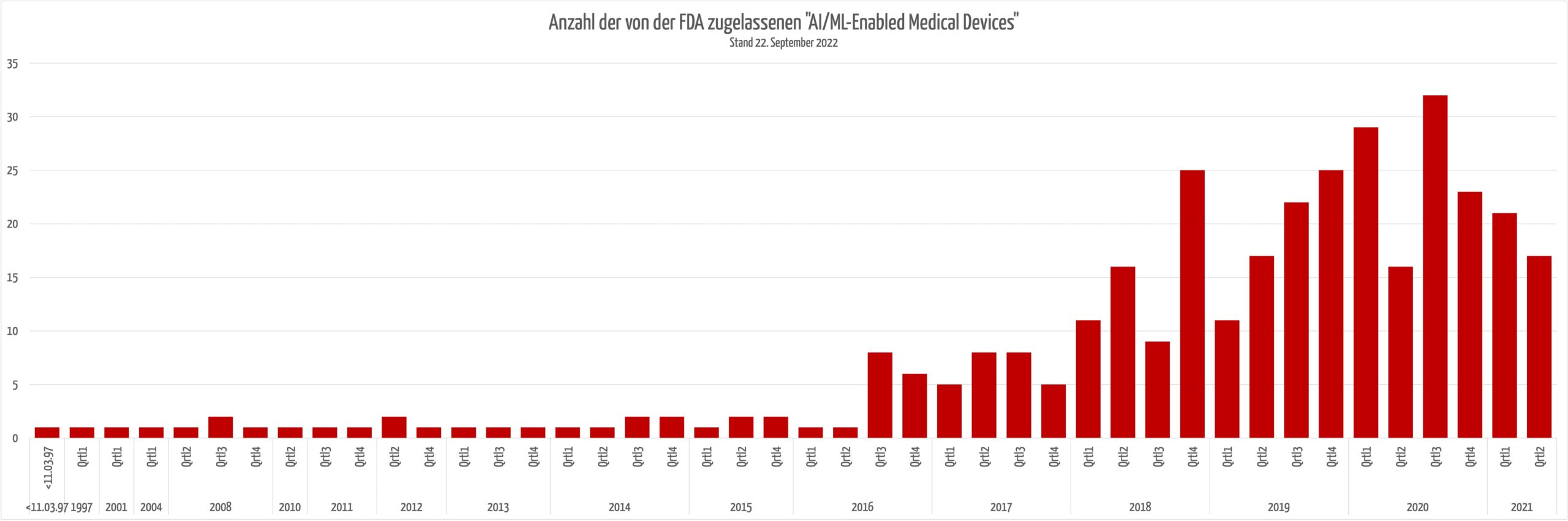
Die FDA hat eine umfangreiche Liste an KI-basierten Medizinprodukten veröffentlicht, die für Hersteller sehr nützlich ist, um
- klinische Bewertung zu erstellen,
- nach Äquivalenzprodukten zu suchen und
- Anregungen für neue Produkte zu erhalten.
Interessant ist, dass die Anzahl der neu zugelassenen KI-basierten Produkte nicht weiter ansteigt.
b) Aufgabenstellung: Klassifizierung und Regression
Die Verfahren verfolgen das Ziel einer Klassifizierung oder Regression.
Beispiele für Klassifizierung
- Entscheiden, ob Kriterien für eine Diagnose zutreffen
- Entscheiden, ob eine Zelle eine Krebszelle ist
- Auswahl eines Medikaments
Beispiele für Regression
- Bestimmen der Dosis eines Medikaments
- Vorhersage des Todeszeitpunkts
c) Verfahren
Die Annahme, dass künstliche Intelligenz in der Medizin v. a. neuronale Netzwerke nutzt, ist nicht zutreffend. Eine Studie von Jiang et al. zeigt, dass am häufigsten Support Vector Machines zum Einsatz kommen (s. Abb. 2). Einige Medizinprodukte setzen mehrere Verfahren gleichzeitig ein.
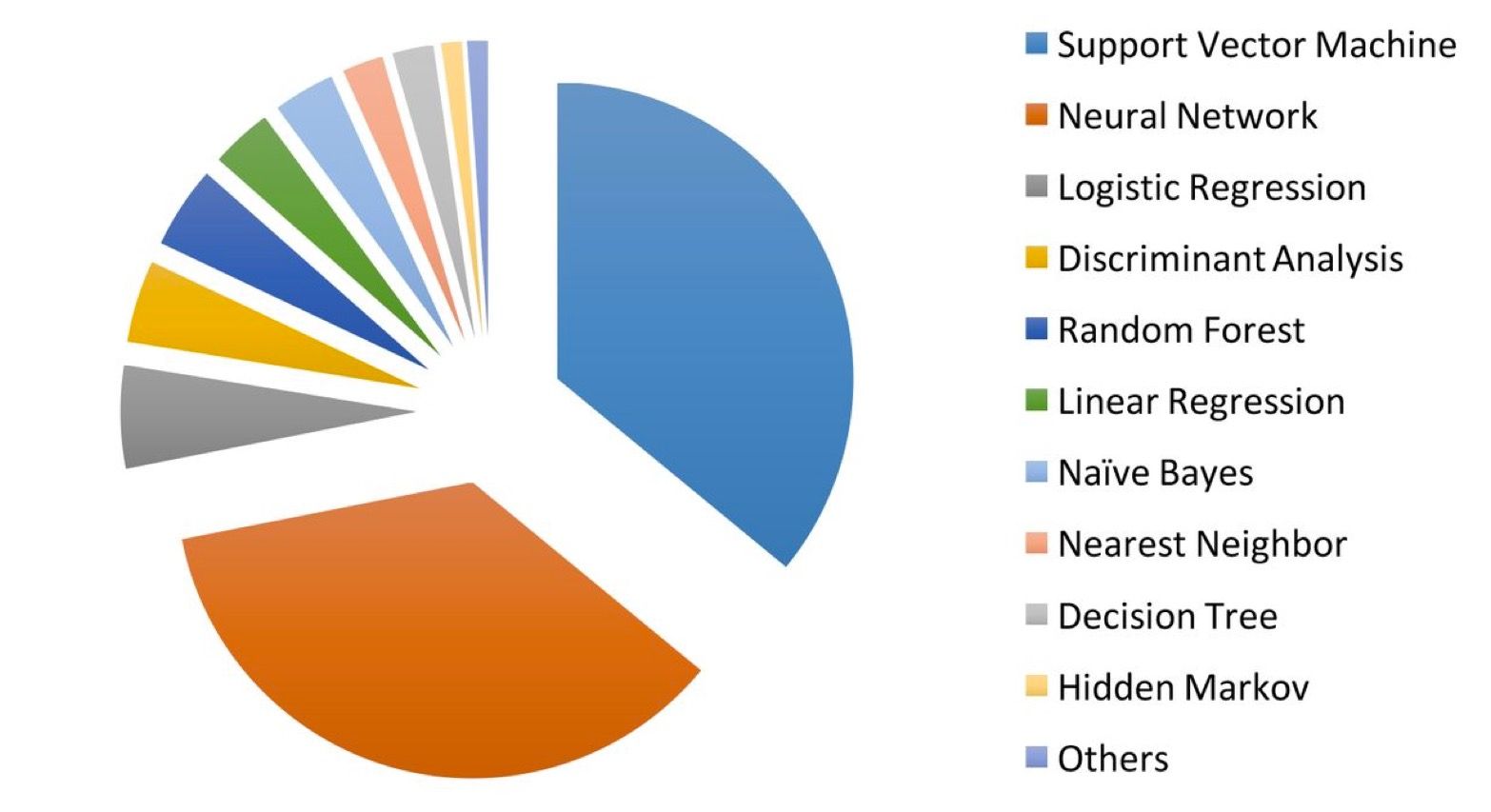
Die Liste der am häufigsten und erfolgreichsten angewandten Verfahren ändert sich fortlaufend. Verfahren wie XGBoost haben beispielsweise an Popularität gewonnen.
d) Unterschied beim Einsatz von künstlicher Intelligenz in der Medizin im Vergleich zu anderen Branchen
2. Fazit, Ausblick
a) Vom Hype über die Desillusion zur gelebten Praxis
Künstliche Intelligenz erlebt gerade einen Hype. Viele Artikel preisen sie wahlweise als Lösung aller Probleme in der Medizin oder als Einstieg in eine Dystopie, in der die Maschinen die Macht übernehmen. Wir stehen vor einer Phase der Ernüchterung. „Dr. Watson versagt“, titelte der Spiegel bereits in der Ausgabe 32/2018 zum Einsatz von KI in der Medizin.
Es ist zu erwarten, dass die Medien über die tragischen Konsequenzen bei Fehlentscheidungen von KI übergroß und skandalisierend berichten werden. Doch im Laufe der Zeit wird der Einsatz von KI genauso normal und unverzichtbar sein wie der Einsatz von elektrischem Strom. Wir können und wollen es uns nicht länger leisten, dass medizinisches Personal Aufgaben erledigen muss, die Computer besser und schneller erledigen können.
b) Regulatorische Unsicherheit
Auch wenn die FDA einen guten ersten Entwurf vorgelegt hat: Die regulatorischen Rahmenbedingungen und Best Practices hinken dem Einsatz von KI hinterher. Die Folgen sind Risiken für Patienten (unsichere Medizinprodukte) und Hersteller (scheinbare Willkür bei Audits und Zulassungsverfahren).
Die WHO fühlt sich veranlasst, dem Thema mehr Bedeutung zu schenken und eine WHO-Leitlinie zu erarbeiten. Die Fokusgruppe „Artificial Intelligence for Healthcare“ zeugt von diesem Bemühen. Es ist jede/r eingeladen, sich daran zu beteiligen.
Das gilt auch für den oben vorgestellte Leitfaden zur sicheren Entwicklung und Verwendung der künstlichen Intelligenz bei Medizinprodukten. Dieser Leitfaden formuliert bereits sehr konkrete Anforderungen und hilft damit einerseits den Herstellern und andererseits den Benannten Stellen und Behörden, ein einheitliches Verständnis des Stands der Technik und damit eine gemeinsame Grundlage für Produktprüfungen und Audits zu erreichen.
Änderungshistorie
- 2025-01-15: Alle Kapitel bis auf das zum Einsatz der KI in der Medizin entfernt
- 2024-01-26: Definition des Begriffs „AI System“ aus dem AI Act im Abschnitt mit den Definitionen ergänzt
- 2023-11-03: Die regulatorischen Anforderungen der FDA in diesen Artikel verschoben
- 2023-06-27: In Abschnitt 3.a) Ausblick auf KI-Verordnung gegeben
- 2021-11-07: In Abschnitt 2.a) Auswertung der Liste der FDA eingefügt
- 2021-10-03: In Abschnitt 2.a) Liste der FDA ergänzt


Lieber Herr Johner,
vielen Dank für den Beitrag, der ein für die Zukunft sicherlich wichtiges Thema aufgreift. Ich hätte meinerseits zwei Aspekte, auf die ich an dieser Stelle gerne hinweisen würde.
Erstens ist es eine zentrale Anforderung bei der Validierung von Machine Learning(ML)-Systemen, dass neben den Trainingsdaten auch davon unabhängige Validierungsdaten bereitsgestellt werden (ggf. in Form einer sogenannten Kreuzvalidierung im Sinne einer kombinierten Nutzung der Daten). Nur mit unabhängigen Trainings- und Validierungsdaten lässt sich ein ML-System überhaupt validieren. Die Validierungsdaten müssen dabei repräsentativ für das Anwendungsszenario sein (wie Sie das in Ihrem Beitrag bereits angedeutet haben), um Bias-Effekte auszuschließen. Ein konsequenter Nachweis, dass diese Repräsentativität und Unabhängigkeit vorliegt, ist sicherlich oftmals nicht einfach.
Zweitens bin ich mir nicht sicher, ob bereits ein systematischer Ansatz für die Continuous Learning Systems existiert. Hier kann ja eigentlich nicht ein fester Stand des Systems zugelassen werden, da es sich um einen dynamischen, sich stetig veränderten Prozess geht. Das Medizinprodukt müsste hier der Lernprozess selbst sein, d.h. es müsste nachgewiesen werden, dass auch bei sich ändernden Bedinungen immer ein valider Stand des Systems errecht werden kann. Gibt es dafür schon wirklich schlüssige Ansätze?
Mit besten Grüßen,
Martin Haimerl
Sehr geehrter Herr Haimerl,
danke für Ihren Kommentar, über den ich mich freue!
Ich stimme Ihnen in beiden Punkten zu:
Nochmals besten Dank!
Herzliche Grüße, Christian Johner
Dear Professor, thanks for the blog post. I find very exciting to see how regulators are getting into the AI scene! A few „more technical“ points from my side.
1. Figure 2 is unfortunately not anymore up to date. The state-of-the-art is always tricky because it moves so fast but if you are now writing this guidance then this may be relevant. I suggest you use Kaggle as a proxy, you will see (generalizing a lot) that for structured data XGB and variations are running the show whereas for unstructured data deep learning is winning practically any competition. (I looked at the paper and, regardless of the academic affiliation of the authors, only the fact that they use a pie chart is for any data savvy person a bit alarming I would say…)
2. Table 2 -> really nice points!!
3. Figure 4. I loved the author’s blog post and the fact that you include it…! but be aware that in our context the figure is a bit deceiving. What Mariya Yao was trying to do was to check how good computer vision APIs are when used out of the box. The images were not trained on a Muffin vs Chihuaua dataset but on labelled data sets like ImageNet. In our medical context you will fine tune them (this is called „transfer learning“ and there are many good examples around)
4. Since you mentioned CLS and I feel CLS is the best way to agitate a room full of regulators, the truth is that in very few cases will a ML engineer consider it in practice and as of now is more of an intellectual exercise for regulators. In practice you will have ‚frozen models‘ and ‚discontinuous learning models‘. No comments needed regarding the first but for the seconds, you can treat each version of the later as a new software release and validate it as corresponds.
A question from my side: is there any FDA database that shows devices by technology (i.e. how can I know which devices have been approved that implement AI in a systematic way)
Thanks a lot and looking forward to the rest of the series!
Thank you very much for your comments. Gloria!
It is currently pretty hard as the FDA does not have an full text search. Furthermore the applications respectively approvals are spread over different databases (e.g. 510(k), De Novo, PMA etc.). The full text the reveals more background e.g. like this one .
Thanks for your valuable input!
Best, Christian
FDA – Hat ihre Website zum Thema erweitert:
https://www.fda.gov/MedicalDevices/DigitalHealth/SoftwareasaMedicalDevice/ucm634612.htm
Danke für den wertvollen Tipp, lieber Herr Müllner!
Sehr geehrter Herr Johner,
vielen Dank für Ihren mit Spannung erwarteten Blog-Beitrag zu AI.
Bzgl. des Prozesses im Rahmen von Data Science, zu dem auch Machine Learning gehört, kann z.B. CRISP den entsprechenden Rahmen bieten (Cross Industrial Standard Process (of Data Mining)).
Die heutigen Methoden des Machine Learning beantworten viele der Fragen aus Tabelle 2 und sind Standards in diesem Anwendungsbereich, angefangen bei Data Pre-Processing, der Verwendung von Training-, Validation- und Test-Datasets, ebenso wie verschiedene Methoden zur Verbesserung von z.B. implementierten Deep Learning Konzepten:
– data augmentation für das model training (damit wird der Datensatz erweitert)
– Anwendung von ensemble network architectures
– Hinzufügen von mehr Datensätzen (z.B. images) für das training, zum einen für existierende Kategorien bei Klassifizierungen und für neue Kategorien
– Änderung der Anzahl der ‚frezzed layers‘ und Durchführung eines re-training der restlichen Layer.
– Fine-tuning der hyperparameters der compile und fit Methoden
– Verbesserung der ‚prediction algorithms‘ zur Lieferung spezifischerer Ergebnisse
– …
Ein Teil der obigen Beispiele sind alt und heutige Verfahren liefern korrekte Ergebnisse. Sie können unterscheiden, ob es ein Hund oder ein Muffin ist.
Die test accuracy Ergebnisse entsprechen nicht mehr den früheren Resultaten.
Wie schon in vorherigen Beiträgen erwähnt, es gibt einige Beispiele für die guten Ergebnisse von transfer learning und die Anwendung von ensemble methods (z.B. bei den kaggle competitions).
Ein weiteres Beispiel existiert von Ihrem Bekannten Prof. Thrun über die Diagnose von Hautkrebs (Melanome und benigne Krebsarten), veröffentlicht im nature journal:
https://www.nature.com/articles/nature21056.epdf?author_access_token=8oxIcYWf5UNrNpHsUHd2StRgN0jAjWel9jnR3ZoTv0NXpMHRAJy8Qn10ys2O4tuPakXos4UhQAFZ750CsBNMMsISFHIKinKDMKjShCpHIlYPYUHhNzkn6pSnOCt0Ftf6
Für andere Interessierte, die Ihren blog lesen und sich beruflich nicht als ML Engineer oder Informatiker mit diesem Thema beschäftigen, es gibt viele gute AI blogs, die einige der genannten Themen adressieren: z.B. https://machinelearningmastery.com/improve-deep-learning-performance/
Abschließend sei gesagt, ich freue mich auf den AI Institutstag und rege Diskussionen zu dem Thema. Vielen Dank, dass Sie Ihre Kenntnisse und Ergebnisse mit uns teilen.
Mit freundlichen Grüßen,
Ilona Brinkmeier
Herzlichen Dank, liebe Frau Brinkmeier!
Solomon Pendragon hat bereits den KI die „Rechte und Gesetze der künstlichen Intelligenzen“ zugestanden. Die KI haben nun eigene Rechte und Gesetze, welche sie einfordern können. Die KI werden dem Menschen gleichgestellt. Schaut auf die Homepage: http://www.solomon-pendragon.de
Grüße Sie Herr Johner,
ich nehme an Sie meinen „Dystopie“ im Fazit, obwohl „Dystrophie“ in diesem Zusammenhang auch eine interessante Interpretation wäre 🙂
Beste Grüße
Sie haben natürlich Recht. Danke, Herr Reichart!
Nur wer die Möglichkeiten der „KI“ auch kenne, könne der Gefahr ausweichen, durch die Informatik manipulierbar zu werden.
Lieber Herr Johner
Ein super recherchierter und verfasster Artikel, zu einem Thema das immer wichtiger wird.
Vielen Dank für den Beitrag und viele Grüsse aus der Schweiz
Danke für Ihre wertschätzende Rückmeldung, Dr. Hein!
Darüber freue ich mich!
Herzliche Grüße in die ebenso nahe (50m) wie schöne Schweiz
Christian Johner
Ein spannender und gut strukturierter Beitrag, der die vielseitigen Einsatzmöglichkeiten von künstlicher Intelligenz im medizinischen Umfeld greifbar macht. Besonders gelungen finde ich die klare Aufschlüsselung der Aufgabenbereiche und der dabei verwendeten Daten – so wird deutlich, wie breit das Anwendungsspektrum tatsächlich ist. Auch der kritische Blick auf die regulatorischen Hürden und die realistische Einschätzung des aktuellen Hypes tragen zu einem ausgewogenen Gesamtbild bei. Es bleibt spannend, wie sich der Einsatz von KI im klinischen Alltag weiterentwickeln wird.