
Die Suchfunktion von ClinicalTrials.gov liefert gleichzeitig sowohl unvollständige als auch zu viele Ergebnisse. Das kann fatale Folgen haben.
Doch es gibt einen Weg, mit dem Sie die Aufwände für klinische Bewertungen, klinische Prüfungen und die Post-Market Surveillance minimieren und sogar zusätzliche regulatorische Sicherheit erlangen können.
Ein Beitrag von Prof. Dr. Christian Johner (Johner Institut) und Dr. Daniel Lohner (d-fine)
1. Weshalb Sie mit ClinicalTrials.gov arbeiten sollten
a) ClinicalTrials.gov: Ein Register für klinische Studien
ClinicalTrials.gov ist ein von der US Library of Medicine betriebenes Register, das Informationen über mehr als 330.000 klinischen Studien enthält. Zu diesen Informationen zählen beispielsweise:
- Ziel der Studie
- Studiendesign
- Charakterisierung der Patienten, Ein- und Ausschlusskriterien
- Verwendete Medizinprodukte, Medikamente, Verfahren
- Datum des Beginns, Status, (geplantes) Enddatum
- Relevante Publikationen
- Studienergebnisse
- „Adverse Events“
b) Ein „Muss“ für Medizinproduktehersteller
Nicht erst die EU-Verordnungen (MDR, IVDR) erlegen den Medizinprodukteherstellern umfangreiche Pflichten auf:
- Klinische Bewertung
Die Hersteller müssen im Rahmen der klinischen Bewertung den klinischen Nutzen, die Sicherheit und die Leistungsfähigkeit ihrer Produkte anhand von klinischen Daten nachweisen, bevor sie ihr Produkt auf den Markt bringen können. - Klinische Prüfungen
Verfügt der Hersteller nicht bereits über ausreichende klinische Daten, um diesen Nachweis zu führen, muss er diese Daten erheben – im Rahmen klinischer Prüfungen. - Post-Market Surveillance
Die Hersteller müssen auch nach der Inverkehrbringung die Produkte im Markt überwachen. Bei dieser „Post-Market Surveillance“ sind sie verpflichtet, nicht nur Informationen zu den eigenen Produkten zu sammeln und zu bewerten (z.B. Kundenrückmeldungen, Service-Berichte), sondern auch von vergleichbaren Produkten (z.B. vom Wettbewerb), von vergleichbaren Technologien (z.B. SOUP, Materialien) und alternativen Verfahren (z.B. Chemo- statt Strahlentherapie).
Um diesen gesetzlichen Vorgaben gerecht zu werden, ist das Register ClinicalTrials.gov für Medizinproduktehersteller nicht nur eine Fundgrube an Informationen, sondern auch ein „Must-have“.
Auch unabhängig von den gesetzlichen Pflichten sollten die Hersteller ein Interesse an diesem Register haben: Es kann Ihnen helfen, klinische Studien und damit klinische Daten zu finden. Der Worst Case wäre, wenn Sie diese Daten nicht kennen und eine eigene klinische Prüfungen initiieren. Solch eine klinische Prüfung kann Kosten von mehreren Hunderttausend Euro verursachen.
Beachten Sie, dass die FDA sogar Strafen verhängt, wenn man es versäumt, die Studien zu registrieren! Die Behörde hat dazu ein Guidance Dokument veröffentlicht.
c) Zusammenfassung
Medizinproduktehersteller sollten somit ClinicalTrials.gov für die folgenden, gesetzlich vorgeschriebenen Aufgaben verwenden:
- Informationen sammeln über den Nutzen, die Sicherheit und die Leistungsfähigkeit der eigenen Medizinprodukte anhand der Daten von Äquivalenzprodukten (v.a. für die klinische Bewertung)
- Den Stand der Technik recherchieren einschließlich der Alternativen für die Diagnose, Behandlung, Vorhersage und Überwachung der relevanten Krankheiten und Verletzungen (v.a. für die klinische Bewertung)
- Anhand dieser und anderer klinischer Daten entscheiden, ob eine eigene klinische Prüfung notwendig ist
- Fortlaufend Informationen sammeln über den Nutzen, die Sicherheit und die Leistungsfähigkeit der eigenen Medizinprodukte anhand der Daten von Äquivalenzprodukten (v.a. für die Post-Market Surveillance und den Post-Market Clinical Follow-up). Die klinischen Prüfungen in CT.gov enthalten oft auch einen Verweis auf deren Volltextpublikation.
Für Hersteller, die ClinicalTrials.gov nicht nutzen, besteht die Gefahr einer Nicht-Konformität.
2. Eine Suche, die Sie teuer zu stehen kommen kann
a) Die Probleme bei ClinicalTrials.gov (und anderen Datenbanken)
Problem 1: Der Fluch der ROC-Kurven
Ein perfekter Suchalgorithmus würde alle relevanten Inhalte finden (Sensitivität = 100 %) und die nichtrelevanten Inhalte korrekt herausfiltern (Spezifität 100 %). In der Realität sind Suchalgorithnen aber leider nicht perfekt …
Das Register verfügt über zwei Suchmasken: Die Standardsuche und die „Advanced Search“ (s. Abb. 1).
Die Hersteller stehen vor der Herausforderung, mit den Algorithmen zwei sich oft widersprechende Ziele erreichen zu wollen:
- Hohe Sensitivität der Suchergebnisse: Es sollen möglichst alle Treffer gefunden werden, die für die Fragestellung relevant sind.
- Hohe Spezifität der Suchergebnisse: Es sollen möglichst keine Treffer gefunden werden, die für die Fragestellung nicht relevant sind.
Sogenannte ROC-Kurven zeigen, dass eine höhere Spezifität zu Lasten der Sensitivität führt (s. Abb. 2).

In anderen Worten: Die Hersteller stehen vor dem Dilemma, entweder von zu vielen Suchergebnissen erschlagen zu werden oder nicht alle Treffer zu finden.
Problem 2: Die mangelnde Vollständigkeit der Suchergebnisse
Doch selbst die Hersteller werden enttäuscht, die willens sind, für eine hohe Sensitivität Hunderte „falsch positiver“ Treffer in Kauf zu nehmen: Die Suchergebnisse sind unvollständig, wie das Team des Johner Instituts anhand von Beispielen herausgefunden hat. Teilweise fehlten die Hälfte der relevanten Studien!
Über die Ursachen dieses Problems lässt sich in Unkenntnis der genauen Implementierung nur spekulieren:
- Werden nicht alle Felder in die Suche einbezogen?
- Ist die Suche nicht tolerant genug gegen Rechtschreibfehler in der Suchmaske?
- Berücksichtigt die Suche Synonyme nicht ausreichend?
- Werden Treffer unterbunden, um die Anzahl der Suchergebnisse nicht explodieren zu lassen?
Unsere Vermutung ist, dass nicht alle Felder durchsucht werden. Das ist insbesondere für Medizinprodukte kritisch, da häufig Arzneimittel oder eine Behandlungsmethode im Mittelpunkt der Studie stehen und das Medizinprodukt nur „Nebendarsteller“ ist. Daher findet man diese Produkte nicht immer im Abstract, sondern muss tiefer im Text suchen (z.B. in „Detailed Description“).
Problem 3: Die fragliche Konstanz der Ergebnisse
Offensichtlich arbeiten die Entwickler von ClinicalTrials.gov ständig an der Suchmaschine, ohne Änderungen im Detail zu kommunizieren. Dies führt dazu, dass Suchen mit identischen Suchparametern im Lauf der Zeit zu unterschiedlichen Ergebnissen führen.
Dies ist für Hersteller nicht akzeptabel, die verpflichtet sind, Anforderungen an die Dokumentenlenkung und die Computerized Systems Validation zu erfüllen. Die Wiederholbarkeit von Prozessen im Qualitätsmanagementsystem ist regulatorisch unabdingbar.
b) Was das für Medizinproduktehersteller bedeutet
Für Medizinproduktehersteller ist diese Situation sehr unbefriedigend:
- Die Suche führt zu vielen falsch positiven Treffern.
- Die Suche und die Bewertung der Treffer sind sehr zeitaufwändig.
- Relevante Treffer werden ggf. nicht gefunden.
- Die regulatorische Sicherheit ist nicht gegeben.
Damit ergeben sich bedeutende Nachteile und Gefahren:
- Werden bereits durchgeführte klinische Studien nicht bei den Suchergebnissen angezeigt, laufen die Hersteller Gefahr, eine unnötige klinische Prüfung zu starten. Die Kosten dafür belaufen sich schnell auf Hunderttausende Euro.
- Weil die MDR und die IVDR die Hersteller zu einer kontinuierlichen Post-Market Surveillance und einem regelmäßigen Post-Market Clinical Follow-up verpflichten, müssen die Verantwortlichen diese Suchen und Bewertungen wiederholt durchführen. Das bedeutet Personenwochen an Aufwand, der mit der Anzahl der Produkte wächst.
- Falls Hersteller wichtige Informationen in diesen Datenbanken übersehen oder nicht finden, können sie auf mögliche Sicherheitsprobleme nicht ausreichend schnell reagieren und kompromittieren dadurch die Sicherheit der Patienten.
- Eine technisch und methodisch insuffiziente Suche kann sogar zu Problemen bei Audits und Zulassungen führen.
c) Zusammenfassung: Ein unterschätztes Problem mit weitreichenden Folgen
Wir leben in einer Welt, in der immer mehr Daten gesammelt werden. Das ist gut, denn diese Daten helfen uns, mehr über unsere Produkte zu verstehen: über ihren tatsächlichen klinischen Nutzen, über ihre Sicherheit und über ihre Leitungsfähigkeit.
Es ist ebenfalls gut, dass die Gesetzgeber von den Herstellern verlangen, diese Daten systematisch und zeitnah zu erheben, zu bewerten und notwendige Maßnahmen einzuleiten.
Doch ein „Immer-mehr“ an Daten führt zu einem „Immer-mehr“ an Aufwand für das Erheben und Bewerten dieser Daten. Dazu müssen Datenbanken und Register wie ClinicalTrials.gov zwingend leistungsfähige Suchen ermöglichen. Genau an dieser Stelle scheint es Probleme zu geben.
Die Konsequenzen sind weitreichend: Hersteller müssen immense und teilweise unnötige Aufwände bewältigen. Selbst wenn Sie dazu willens und in der Lage sind, bleibt eine Unsicherheit bestehen: Gefährden die Produkte die Patienten? Drohen Klagen auf Schadenersatz? Werden Sie die nächste Zulassung und das nächste Audit sicher bestehen?
3. Daten aus ClinicalTrials.gov extrahieren
a) Es gibt eine Lösung!
Das Johner Institut entwickelt Wege, um diese Probleme in den Griff zu bekommen und den Herstellern eine automatisierte Lösung anzubieten, die
- die Aufwände für die Suche minimiert,
- die Anzahl relevanter Treffer erhöht,
- die Anzahl nichtrelevanter Treffer reduziert und
- die Risiken unnötiger klinischer Prüfungen und Probleme in Audits minimiert.
Diese Lösung stellt der Artikel im Weiteren am Beispiel von ClinicalTrials.gov vor.
b) Vorgehen
Der technische Ansatz
Die Experten des Johner Instituts haben die Daten von ClinicalTrials.gov (und von vielen anderen Datenbanken) über einen selbst entwickelten Konnektor zusammengeführt (s. Abb. 3).
Dazu verwenden sie eine Microservice-Architektur, die sie in Docker-Container betreiben. Eine datenbankübergreifende Suche steht über eine REST-API als einer dieser Microservices bereit. Neben ClinicalTrials.gov sind weitere Datenbanken angebunden:
- BfArM
- SwissMedic
- FDA (mehrere Datenbanken)
- PubMed
- Social Media
Um relevante Informationen mit hoher Wahrscheinlichkeit zu finden, nutzt die Suche einen Synonym-Service (ein weiterer Microservice), der wiederum Ontologien wie UMLS verwendet.
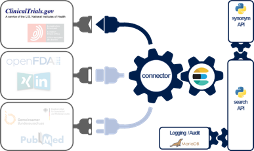
Die komplette Umsetzung basiert auf etablierten und modernen Open-Source-Bibliotheken sowie auf Eigenentwicklungen in Java, JavaScript, Scala und Python.
Diese REST-basierte Suche nutzt das Johner Institut auch im Rahmen seines Post-Market Radars. Es wird diese Suchfunktion auch zur Integration in Hersteller-eigene Systeme anbieten.
Der inhaltliche Ansatz
Die signifikanten Verbesserungen, die der nächste Abschnitt vorstellt, basieren u.a. auf diesen Ansätzen:
- Die Suche nutzt die kompletten Volltexte aller Studiendaten. Das scheint bei der Suche von ClinicalTrial.gov nicht immer gegeben zu sein.
- Ein Algorithmus sortiert die Ergebnisse hinsichtlich der Relevanz für die Nutzer. Dieser Algorithmus bewertet die Relevanz der Datenfelder anhand von vier Kategorien und gewichtet die Ergebnisse entsprechend:
| Kategorie | Datenfelder |
|
1 – sehr hoch |
Titel (Lang- oder Kurztitel) |
|
2 – hoch | Zusammenfassung, Intervention (z.B. mit Medizinprodukt), Gesundheitszustand |
|
3 – mittel |
Detaillierte Beschreibung, Studiendesign, Keywords |
|
4 – niedrig |
Sonstiger Inhalt, lexikalisch weniger strenge Eingrenzung (z.B. ohne Bindestriche) |
Basierend auf mehr als Tausend klassifizierten Trainingsdatensätzen haben unsere ML-Experten die zentralen Einflussfaktoren auf die Relevanz gemessen und von Fachanwendern validieren lassen. Dazu später mehr.
c) Diese Ergebnisse haben wir erzielt
Das Team hat 30 klinische Bewertungen bzw. repräsentative Suchanfragen ausgewählt. Anhand dieser hat es die Ergebnisse von ClinicalTrials.gov und der eigenentwickelten Suche verglichen. Die Güte dieser Ergebnisse hat alle Beteiligten überrascht.
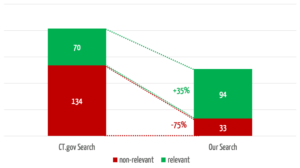
Die selbst entwickelte Suche hat über ein Drittel mehr relevante Treffer gefunden (s. Abb. 4). Dabei findet sie in 3 der 30 Suchen relevante Studien, bei denen bei die Vergleichssuche über ClinicalTrials.gov gar nichts findet.
Gleichzeitig reduziert die eigene Suche die Anzahl der nichtrelevanten Treffer um 75 %, was den Anwendern einen erheblichen Zeitaufwand erspart.
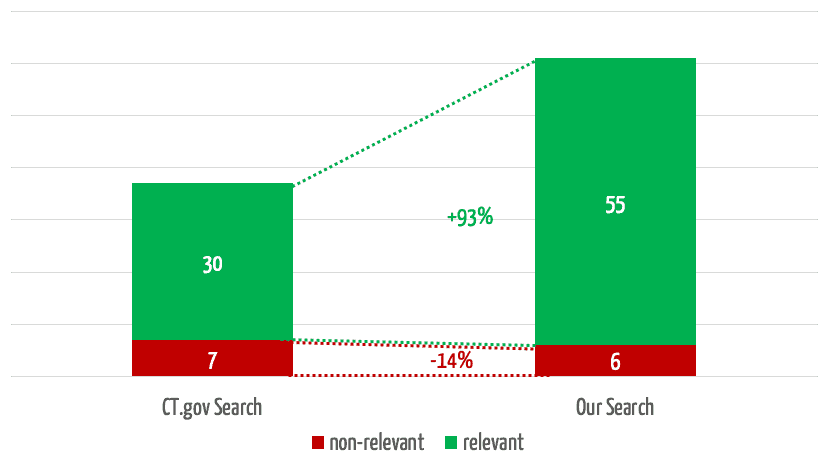
Betrachtet man nur die ersten fünf Treffer, welchen erfahrungsgemäß die größte Aufmerksamkeit zukommt, findet die eigene Lösung fast doppelt so viele relevante Treffer (Abb. 5).
d) Ein Blick unter die Haube
Die Anwender möchten, dass die für sie relevantesten Treffer zuerst angezeigt werden. Abbildung 6 zeigt einen Vergleich zwischen der automatischen Zuordnung von Treffern in die vier Kategorien „sehr hoch“ bis „niedrig“ und einer Bewertung durch Fachanwender („relevant“ bzw. „nicht relevant“).
Die erfolgreiche Trennung zwischen relevanten und irrelevanten Treffern lässt sich deutlich erkennen: Die Kategorien „sehr hoch“ und „hoch“ weisen über 80 % der für Fachanwender relevanten Treffer auf. Es hängt somit davon ab, in welchen Datenfeldern die Suchbegriffe vorkommen.
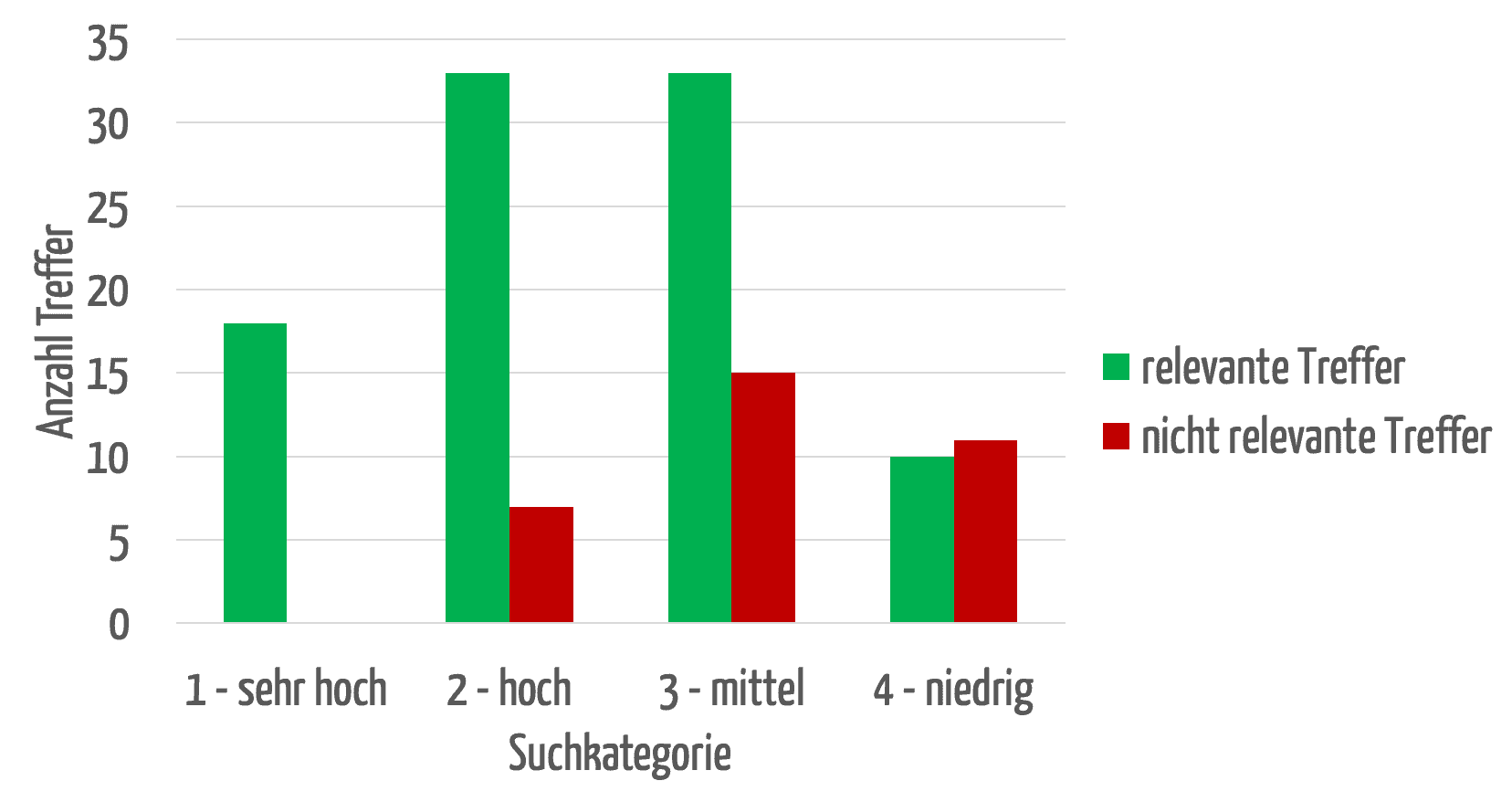
Abbildung 7 zeigt, dass die Relevanz der gefundenen Treffer bei der höchsten Kategorie auch am höchsten ist und bei den niedrigeren Kategorien erwartungsgemäß sinkt.
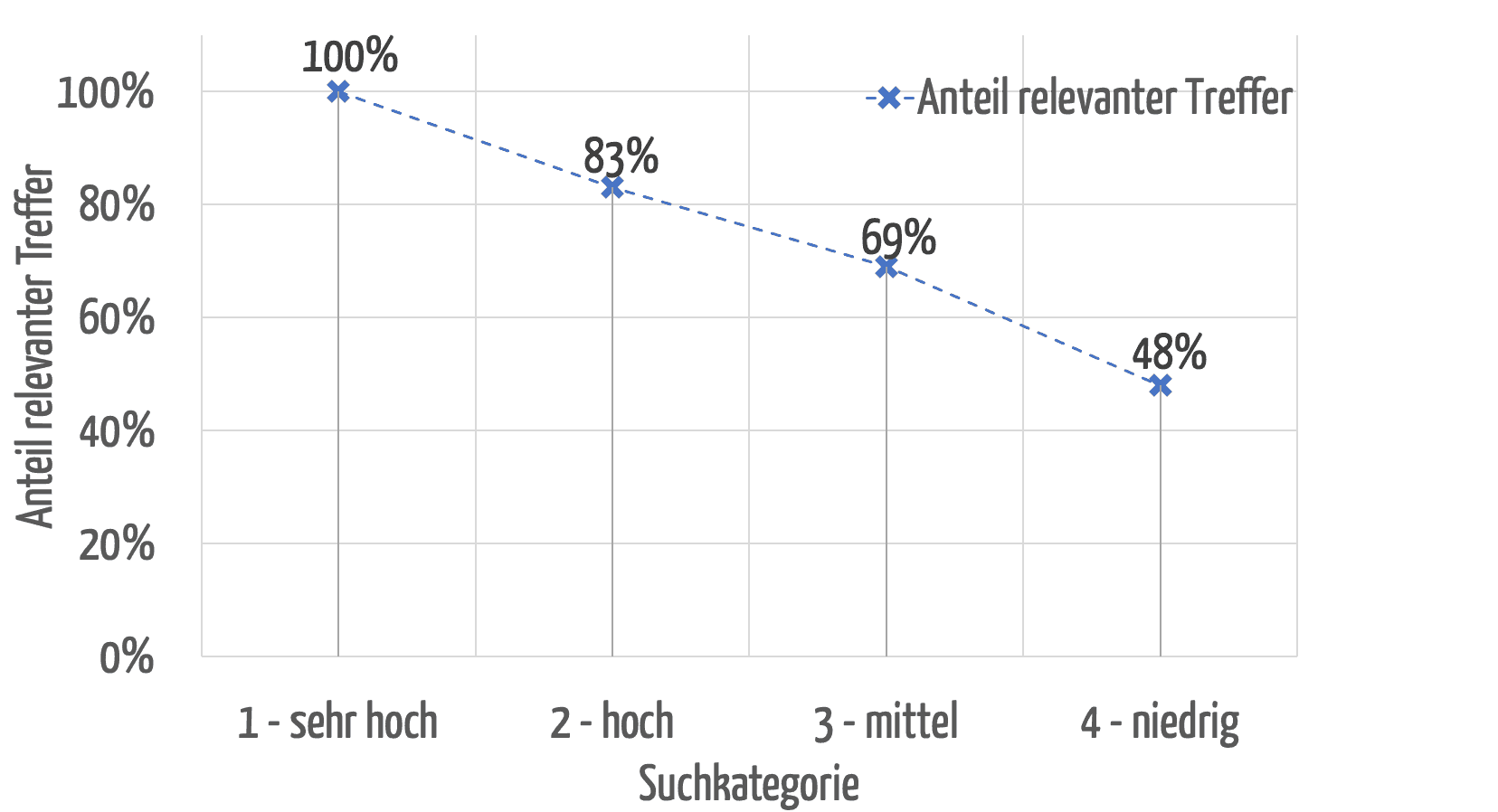
Ein weiterer, zentraler Mehrwert dieses Bewertungsmodells ist seine Vergleichbarkeit. Da ein absolutes Ranking erstellt wird, können nicht nur die Ergebnisse einer Suchanfrage sortiert, sondern auch verschiedene Suchanfragen miteinander verglichen werden. Beispielsweise kann ein Anwender erkennen, dass er/sie seine Suchanfrage vermutlich treffender formulieren kann, wenn seine/ihre Recherche nach einem viel genutzten, lange am Markt existierenden Produkt ausschließlich Treffer der Kategorie 4 liefert.
e) Zusammenfassung
Normalerweise gelingt es nicht, sowohl die Sensitivität als auch die Spezifität einer Suche zu erhöhen. Doch die Ergebnisse beweisen das Gegenteil: Beide Wünsche sind gleichzeitig besser erfüllbar. Die ROC-Kurve des von uns entwickelten Suchalgorithmus ist nicht perfekt, aber deutlich besser als die von ClinicalTrials.gov.
Nicht nur das: Die Suchergebnisse sind auch besser nach Relevanz sortiert.
All das trägt dazu bei, die ersehnten Ziele zu erreichen:
- Weniger Aufwand beim Aussortieren nichtrelevanter Ergebnisse
- Höhere Sicherheit, relevante Treffer zu finden und damit
- unnötige klinische Prüfungen zu vermeiden,
- wesentliche klinische Daten und damit Sicherheitsprobleme zu übersehen
- Regulatorische Sicherheit auch dadurch, dass der Suchprozess unter Kontrolle ist
- Flexibilität beim Anzeigen relevanter Kontextdaten, um eine noch schnellere Bewertung der Suchergebnisse zu erreichen
- Vertrauen in die Suchergebnisse, da die Funktionsweise des Algorithmus transparent ist
- Möglichkeit, Suchen und Suchergebnisse zu speichern und so bei Updates Arbeit zu sparen
4. Was wir uns erträumen würden
Diese ermutigenden Ergebnisse wecken den Appetit auf mehr: Was bei ClinicalTrials funktioniert, sollte doch auch bei anderen Datenbanken funktionieren. Und weshalb sucht die Maschine dann nicht gleich selbst die Ergebnisse, wertet diese aus und verfasst die Berichte?
a) Die ideale Suche
Eine ideale Suchmaschine weist die folgenden Merkmale auf:
- „One-Stop-Shop“
Die Suche muss über alle relevanten Datenquellen erfolgen: von der klinischen Fachliteratur und die Bug-Reports der SOUP-Hersteller über Behördendatenbanken wie die der FDA und des BfArM bis hin zu IT-Security-Datenbanken (z.B. NIST), klinischen Studiendatenbanken (v.a. CT.gov) und Audit-Logs der eigenen Produkte. - Maximale Sensitivität und Spezifität
Die ideale Suche würde alle relevanten Treffer finden, keinen mehr und keinen weniger. - Sortierung nach Relevanz
Die relevantesten Ergebnisse stünden oben, sodass man abhängig vom Zeitbudget entscheiden könnte, wie viele Treffer man bewertet. - Kontextualisierung
Wenn die Suchergebnisse bereits einen kurzen Kontext in Form der wichtigsten Aussagen schafften, könnte man schnell und einfach entscheiden, ob man das ganze Suchergebnis (z.B. den ganzen Artikel) lesen muss. - Fehlertoleranz
Die perfekte Suche könnte damit umgehen, dass wir eben nicht perfekt sind. Beispielsweise würde sie Rechtschreibfehler korrigieren und Begriffe durch geeignetere Synonyme ersetzen. - Usability
Die Suche muss so einfach zu bedienen sein, wie wir das von z.B. Google kennen. Im Zweifelsfall sollte das System nachfragen und den Anwender führen.
b) Der ideale Prozess
Der zweite Wunsch besteht darin, dass ein System den Anwendern die aktive Suche abnimmt.
- Es würde automatisiert und kontinuierlich nach neuen Daten suchen.
- Relevante Treffer würde es automatisch einer Vorbewertung unterziehen und den Analysten mit einem Bewertungsvorschlag zur Entscheidung vorlegen. Die endgültige Entscheidung würden z.B. Kliniker, Sicherheitsbeauftragte oder Risikomanager treffen.
- Die endgültige Bewertung würde einen fertigen Bericht (z.B. Post-Market Surveillance Report bzw. Periodic Safety Update Report) erzeugen.
- Zudem würde das System anhand dieser Entscheidungen weiter trainiert und verbessert.
5. Fazit, Zusammenfassung, Empfehlung
a) Die manuelle Suche über Suchmasken ist nicht die Zukunft
Die Digitalisierung führt dazu, dass Hersteller in einem Meer an Daten ertrinken, die in einer Unzahl an Datenbanken gespeichert und über umständliche und fehlerträchtige Suchmasken zugänglich sind. Doch das darf nicht sein. Denn sonst werden die Hersteller
- die Aufwände für die kontinuierliche Suche und Bewertung dieser Daten nicht mehr leisten können,
- unnötige regulatorische Risiken eingehen, weil die Suchergebnisse unvollständig sind und die Suchprozesse nicht validiert und reproduzierbar sind,
- in Gefahr laufen, unnötige klinische Prüfungen durchzuführen, weil vorhandene klinische Daten nicht gefunden wurden,
- Informationen über Sicherheitsprobleme nicht oder nicht rechtzeitig erhalten und entsprechend nicht zeitnah und gesetzeskonform reagieren können,
- nicht mitbekommen, wie sich der Markt, die Wettbewerber und der „State of the Art“ weiterentwickeln, was zu Fehlentscheidungen führt.
b) Die Automatisierung führt zur Lösung
So wie die Digitalisierung Auslöser dieser Herausforderungen ist, muss sie auch zu deren Lösung beitragen. Das in diesem Artikel vorgestellt Beispiel zeigt, dass es möglich ist,
- automatisiert und damit kostengünstig und schnell die relevanten Informationen zu finden und Aufwände für die Bewertung nichtrelevanter Informationen zu minimieren,
- Kosten für unnötige klinische Studien zu minimieren,
- gleichzeitig die regulatorische Sicherheit zu erhöhen,
- die Sicherheit der eigenen Produkte zu erhöhen und
- dem Unternehmen durch eine bessere „Market Intelligence“ einen Wettbewerbsvorteil zu verschaffen.
Die Hersteller werden auch bei einem hohen Automatisierungsgrad weiterhin Menschen benötigen. Doch deren Aufgaben werden nicht mehr in Routinetätigkeiten liegen, sondern sich auf wenige, aber schwierige Bewertungen und Entscheidungen konzentrieren.
c) Ihre nächsten Schritte
Wie in allen Bereichen sollten Hersteller auch bei der klinischen Bewertung, bei der Post-Market Surveillance und beim Post-Market Clinical Follow-up ihre Prozesse digitalisieren. Dazu gibt es mehrere Möglichkeiten:
- Selbst oder mit Hilfe von Dienstleistern die Infrastrukturen und Algorithmen entwickeln und betreiben
- Vorhandene Dienste (z.B. über Webservices bereitgestellte Algorithmen) in die eigene Infrastruktur integrieren
- Prozesse outsourcen und so Aufwände reduzieren und vom „Leverage“ profitieren
Das Johner Institut unterstützt Sie bei allen Alternativen. Melden Sie sich, wenn Sie mehr erfahren möchten.
„Conflicts of Interest“
Das Johner Institut bietet Medizinprodukteherstellern mit dem Post-Market Radar ein Outsourcing der Post-Market-Surveillance an. Dieser Service nutzt die in diesem Artikel vorgestellten Technologien und Konzepte. Es wird zudem künftig die datenbankübergreifende Suche als Webservice zur Verfügung stellen.
Die Firma d-fine unterstützt Firmen branchenübergreifend bei Integrations- und Entwicklungsprojekten, z.B. im Bereich Machine Learning.
Das Johner Institut hat bei der Entwicklung der Suchalgorithmen die Dienste von d-fine genutzt.


{kind=link}