
Die Fehlerwahrscheinlichkeit bei Software lässt sich schwer abschätzen. So schwer, dass die „alte“ DIN EN IEC 62304:2006 schrieb: „Es gibt jedoch keine Übereinstimmung, wie die Wahrscheinlichkeit des Auftretens von Software-Ausfällen unter Verwendung von traditionellen statistischen Methoden bestimmt werden kann.“
Die Norm schlussfolgerte, dass „die Wahrscheinlichkeit einer solchen Fehlfunktion als 100 Prozent angenommen werden muss“. Die hochproblematische Forderung ist in der „neuen“ IEC 62304:2015 gestrichen.
Dieser Artikel schildert, wie Sie die Fehlerwahrscheinlichkeit bei Software realistisch abschätzen können und wann Sie das durchführen müssen.
1. Fehlerwahrscheinlichkeit bei der IEC 62304
a) Probleme mit der „alten“ DIN EN IEC 62304:2006
Die DIN EN IEC 62304:2006 (Medical Device Software – Software Life Cycle Processes) verlangt: Die Wahrscheinlichkeit eines Softwarefehlers, der zu einer Gefährdung führen kann, muss mit 100 % angenommen werden.
„Wenn die GEFÄHRDUNG davon herrühren könnte, dass das SOFTWARE-SYSTEM sich nicht entsprechend seiner Spezifikation verhält, muss die Wahrscheinlichkeit einer solchen Fehlfunktion als 100 Prozent angenommen werden.“
IEC 62304:2006
Eigentlich wollten die Autoren damit ausdrücken: Man soll nicht mit der Fehlerwahrscheinlichkeit bei Software argumentieren.
„Working in ISO/IEC JWG3 I followed these discussions and want to point out, that this 100% assumption is used for the safety classification only – and it is NOT used for reasoning about ACCEPTABLE or ALARP in some Risk Analysis.“
Georg Heidenreich (NAMed, DIN-Normenausschuss Medizin)
Ein gewichtiges Problem, das man sich damit einhandelt, ist offensichtlich: Unterstellt man bei einer Standalone-Software eine Fehlerwahrscheinlichkeit von 100 %, dann ist die Wahrscheinlichkeit des Schadens sehr hoch und das damit verbundene Risiko selten akzeptabel (Abbildung 1):
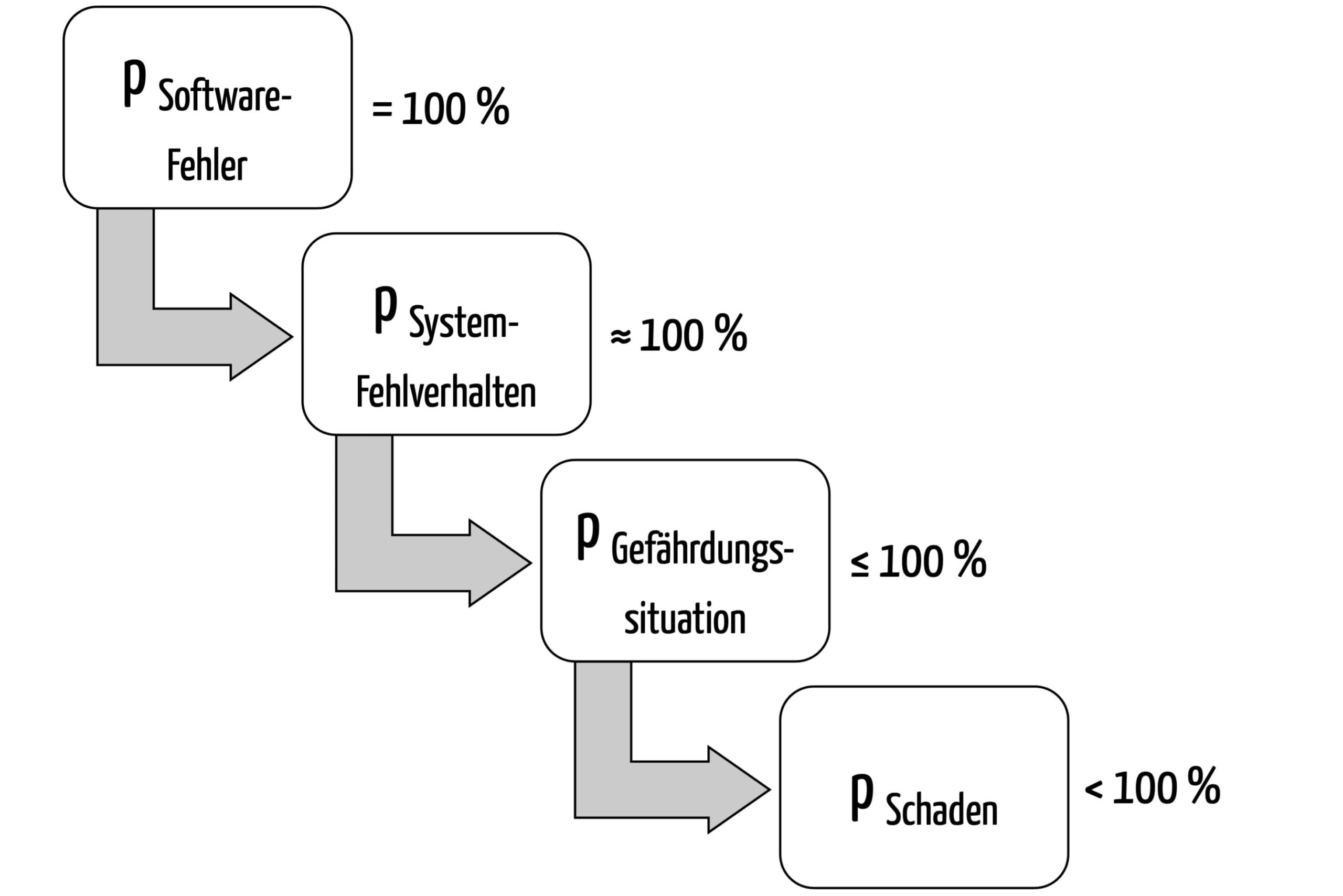
Ein Softwarefehler (hier angenommen mit 100 % Wahrscheinlichkeit) könnte wie folgt zu einem Schaden führen:
- Die Software arbeitet inkorrekt: Sie zeigt fast immer (in ca. 100 % der Fälle) ein falsches Medikament an.
- Die Höhe der Wahrscheinlichkeit, dass dies tatsächlich zu einer Gefährdungssituation führt (z. B. Einnahme eines falschen Medikaments) hängt davon ab, wie wahrscheinlich es ist, dass der Fehler entdeckt wird. Diese Wahrscheinlichkeit liegt unter 100 %.
- Die Wahrscheinlichkeit, dass deshalb auch ein Schaden mit einem bestimmten Schweregrad (z. B. anaphylaktischer Schock) eintritt – und damit die Höhe des Risikos (!) – hängt davon ab, wie gut der Patient die Fehldosierung verträgt. Sie dürfte definitiv geringer sein als 100 %.
Je nach Kontext ergibt sich eine Schadenswahrscheinlichkeit zwischen 1 % und weniger als 100 %. In aller Regel jedoch dürfte das damit verbundene Risiko nicht akzeptabel sein.
Sie können in solchen Fällen also nicht sinnvoll mit einer 100%-igen Wahrscheinlichkeit agieren. Stattdessen möchten Sie die wirkliche Wahrscheinlichkeit von Softwarefehlern abschätzen und daraus das Risiko bestimmen.
b) Die „neue“ IEC 62304:2015 streicht den fatalen Passus
Die gute Nachricht lautet hier: In Amendment I der „neuen“ IEC 62304:2015 ist der Stein des Anstoßes entfernt (Abbildung 2).

Dafür schreibt die Norm jetzt: „There is no known method to guarantee 100 % SAFETY for any kind of software.“ Dieser Trivialaussage kann man in den für Medizinproduktehersteller relevanten Fällen zustimmen. (Anmerkung: Den Begriff Safety in diesem Zusammenhang zu nutzen, könnte man in einer nächsten Version der Norm überdenken.)
Die „neue“ IEC 62304 schreibt zwar auch noch: „Probability of a software failure shall be assumed to be 1“. Doch macht die Norm klar, dass sie dies nur für einen ganz bestimmten Kontext meint: „In determining the software safety classification of the software system“.
Die IEC 62304:2015 sagt somit nicht, dass für Software stets eine 100%-ige Fehlerwahrscheinlichkeit anzunehmen ist. Für Risikoeinschätzungen beispielsweise dürfen Sie mit realistischeren Fehlerwahrscheinlichkeiten agieren.
2. Definition der Fehlerwahrscheinlichkeit bei Software
Bei Fehlern gilt es zu unterscheiden zwischen Fehlerzuständen und Fehlerwirkungen. Sie werden wie folgt definiert:
Fehlerhafter Programmteil, Anweisung oder Datendefinition, die ursächlich für eine Fehlerwirkung verantwortlich ist
ISTQB-Glossar
Die Wirkung eines fehlerhaften Zustands, der während der Ausführung des zu testenden Programms nach außen für den Anwender sichtbar auftritt
ISTQB-Glossar
Nicht jeder Fehlerzustand führt auch zu einer Fehlerwirkung. Beispielsweise führt der Aufruf einer Methode auf einem nicht initialisierten Objekt nicht zu einer Fehlerwirkung, wenn dieser Code nie durchlaufen wird oder wenn eine Fehlerbehandlung diesen Fehler fängt und neutralisiert.
In diesem Artikel verstehen wir unter „Fehlerwahrscheinlichkeit“ die Wahrscheinlichkeit einer Fehlerwirkung.

Erstellen Sie eine regulatorisch konforme Risikomanagementakte – schnell und auditsicher
Mit Hilfe von Mustervorlagen und Videos lernen Sie, wie Sie eine vollständige Risikomanagementakte mit allen notwendigen Dokumenten erstellen. Prüfen Sie Ihre Dokumente selbst auf Gesetzeskonformität und vermeiden Sie Fehler bei Audits und Einreichungen.
3. Abschätzen der Fehlerwahrscheinlichkeit bei Software
Eine maximale Wahrscheinlichkeit als Zielwert festzulegen, ist eine Sache. Herauszufinden, ob man diesen erreicht hat, eine andere.
a) Literaturdaten
Literaturwerte können beim Abschätzen von Fehlerwahrscheinlichkeiten helfen:
- Pro 1000 Zeilen eines sicherheitskritischen Systems fanden sich 1,4 kritische und 23 unkritische Fehler.
- Bei kommerzieller Software wie Windows XP geht man von 30 Fehlern pro 1000 Zeilen aus, was bei 35 Mio. Zeilen mehr als 1 Mio. Fehlern entspricht. Dennoch hat Windows XP eine MTBF (mean time between failures) von 300 Stunden.
- Bei Autos und Flugzeugen geht man von 10E-7 Softwarefehlern pro Stunde aus. (Diese Zahlen stehen nicht im Widerspruch zu den Forderungen an die Fehlerwahrscheinlichkeit von Verkehrsmitteln.)
Es bleibt das Problem: Diese Daten helfen zwar bei der Abschätzung von Fehlerwahrscheinlichkeiten, stellen aber keinen Beweis dar, dass diese tatsächlich erreicht werden.
b) Ausprobieren
Die tatsächliche Wahrscheinlichkeit, auf Fehlerzustände zu stoßen, liefert erst die Praxis bzw. das Ausprobieren. Hierfür gibt es zwei Ansätze:
- Testen
- Im Produktiveinsatz beobachten
1. Testen
Testen hilft, zumindest eine obere Grenze der Wahrscheinlichkeit von Fehlern abzuschätzen. Selbstredend muss dazu beim Testen der Code überhaupt durchlaufen werden. Eine möglichst vollständige Testabdeckung (lesen Sie hier mehr über Code Coverage) ist eine notwendige Voraussetzung, um belastbare Zahlen (MTBF, Fehlerwahrscheinlichkeit, Fehler pro 1000 Zeilen Code (kLoC)) abzuleiten.
Die Mutation von Code gibt weitere Hinweise darauf, wie sensitiv die gewählten Testfälle tatsächlich Fehler aufspüren.
In jedem Fall sollten alle Benutzungsszenarien getestet werden.
Die Testdauer ist insbesondere bei automatisierten Tests kein aussagekräftiges Maß für die Güte bzw. Vollständigkeit (wie an anderer Stelle behauptet).
2. Produktiveinsatz
Die „repräsentativsten Testfälle“ und damit die belastbarsten Zahlen erhalten Sie aus dem Feld. Nutzen Sie dazu:
- Rückmeldungen der Anwender
- Eigene Beobachtungen
- Auswertungen von Fehler- und Audit-Logs
- Befragungen der Anwender
- Auswertung der eingegebenen Daten
Nutzungsstatistiken helfen Ihnen zu überprüfen, ob Ihre Tests alle tatsächlichen Benutzungsszenarien abdecken.
Allerdings: Bei der Zulassung eines neuen Produkts stehen diese Daten i. d. R. nicht zur Verfügung.
Wenn diese Daten fehlen sollten, dann beachten Sie:
- Vergleichbare Vorgängerprodukte liefern Ihnen ziemlich gute Anhaltspunkte.
- Bedienen Sie sich der Fehlerdatenbanken der FDA und des BfArMs.
- Tests helfen Ihnen, eine Obergrenze von Wahrscheinlichkeiten abzuschätzen.
d) Modellierung und Berechnung
Mathematische Modelle wie Markov-Ketten helfen, die Wahrscheinlichkeiten zu berechnen, mit denen sich Fehler fortpflanzen. Diese Wahrscheinlichkeiten lassen sich oft gerade nicht als das Produkt der Einzelwahrscheinlichkeiten berechnen.
Eine Übersicht und kurze Einführung verschafft Ihnen Anhang D der IEC 61508-3, insbesondere in den Teilkapiteln D.3 bis D.7.
In der Praxis finden diese Verfahren bei Software (!) allerdings kaum Anwendung. Das ist u. a. begründet
- in deren Komplexität,
- in der schwierigen Übertragbarkeit auf Software und
- in der mangelnden Abbildung der Software auf ein Modell.
e) Code-Coverage-Daten
Es gibt einige Arbeiten, die das Verhältnis zwischen Code Coverage und Fehlererkennung untersuchen.
Gopinath et al. stellen bei der Auswertung hunderter Open-Source-Projekte fest, dass (konträr zu einigen wissenschaftlichen Studien) der Statement Coverage im Vergleich zum Branch Coverage oder Path Coverage die beste Vorhersage für die Qualität liefert. Dies wurde nicht nur durch manuell gebaute, sondern auch durch automatisch generierte Tests gezeigt.
Die folgende Abbildung stammt aus der verlinkten Veröffentlichung. Sie zeigt das Verhältnis zwischen Statement Coverage und gefundenen Mutationen.
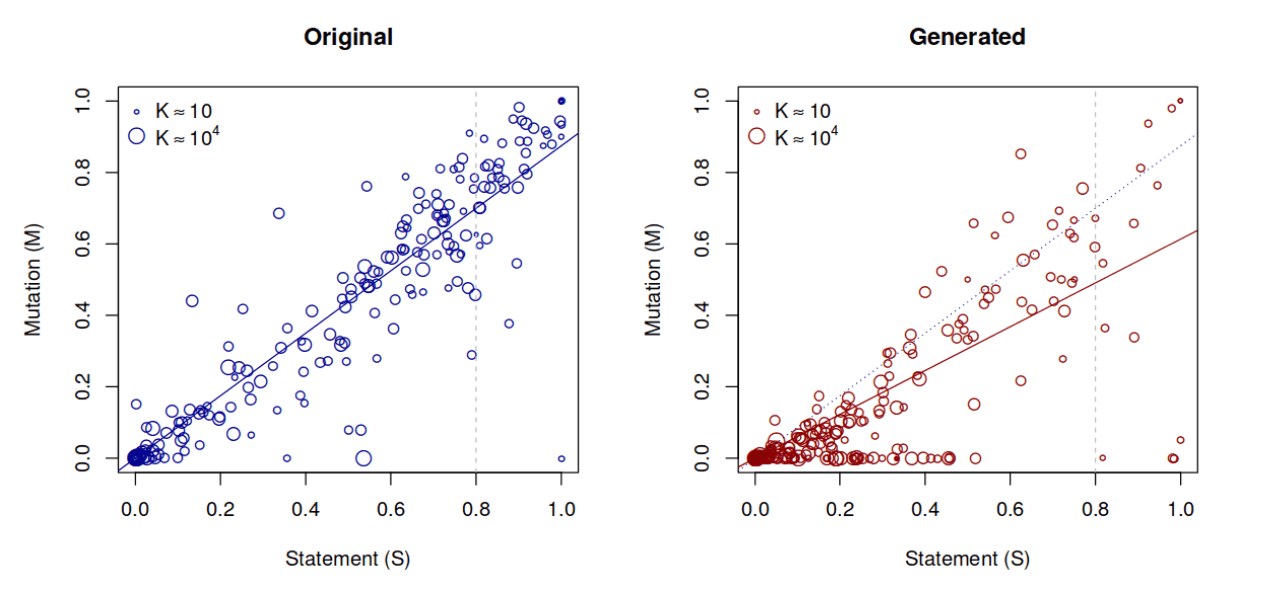
Die Frage „Gibt es eine Korrelation zwischen der Güte des Testens und der Wahrscheinlichkeit eines bestimmten Software-Problems?“ lässt sich klar mit Ja beantworten:
So kann man beispielsweise in einem Projekt, das mit den untersuchten Beispielen vergleichbar ist, erwarten, dass man bei einer Statement Coverage von 80 % etwa 70 % der Fehler findet.
Allerdings sieht man am rechten Plot, dass diese Metrik nicht alleine betrachtet werden sollte, sondern dass auch die Natur der Tests relevant ist: Manuell gebaute Tests scheinen zuverlässiger Fehler zu finden als automatisch generierte. Interessant ist auch, dass die Größe der Test Suite keinerlei Effekt zeigte.
Es bleibt anzumerken, dass es sich ausschließlich um Java-Projekte handelt. Allerdings ist zu vermuten, dass sich diese Korrelation auf andere Sprachen verallgemeinern lässt.
Beachten Sie auch den Artikel zum kombinatorischen Testen. Dieser enthält Literaturquellen, in denen die Anzahl der gefundenen Fehler mit der Testmethode korreliert wird.
f) Fazit
Das Abschätzen der Wahrscheinlichkeit ist schwierig. Na und?
Die Wahrscheinlichkeit von Softwarefehlern ist in der Tat sehr schwierig zu schätzen. Sie können jedoch anhand von Literaturdaten und eigenen Messungen mehr als nur die Größenordnung abschätzen.
Auch andere Wahrscheinlichkeiten sind schwer abzuschätzen, etwa die von Nutzungsfehlern. Allerdings käme hier niemand auf die Idee, deshalb eine Worst-Case-Annahme von 100 % zu fordern, wie das die IEC 62304 tat. Zumindest konnte bzw. musste man die „alte“ Norm so (miss-)verstehen.
Wer seine Software nach den Regeln der Kunst (wie sie die IEC 62304, mehr noch die IEC 61508-3 vorstellt) entwickelt und die Software mit einem Code Coverage (zumindest der relevanten Teile) nahe 100 % testet, sollte von einer Fehlerwahrscheinlichkeit seiner Software von ≤ 10-2 pro Anwendungsfall ausgehen können, selbst wenn die Software neu entwickelt wurde. Die Fehlerwahrscheinlichkeiten von produktiver und bewährter Software dürften mindestens eine Größenordnung kleiner sein.
4. Notwendige Fehlerwahrscheinlichkeit bei Software
Es gibt mehrere Varianten, um die maximale Wahrscheinlichkeit abzuschätzen, mit der eine Software eine (kritische) Fehlerwirkung aufweisen darf.
a) Produktspezifische Risikoakzeptanzkriterien anwenden
Welche Fehlerwahrscheinlichkeit bei einer Software erreicht werden muss, lässt sich aus der Risikoakzeptanzmatrix ableiten: Dazu beginnt man mit einem angenommenen Schaden, liest aus der Akzeptanzmatrix dessen maximale Wahrscheinlichkeit ab und verfolgt die Ursachenkette rückwärts bis zum Softwarefehler (FTA-Ansatz).
Mit anderen Worten: Man geht die in Abbildung 1 gezeigten Schritte in umgekehrter Reihenfolge und schließt von der maximalen Schadenswahrscheinlichkeit auf die maximale Wahrscheinlichkeit eines Softwarefehlers.
b) Andere Akzeptanzkriterien anwenden
Manche Industrien verlangen sehr niedrige Fehlerwahrscheinlichkeiten, etwa 10-9 pro Betriebsstunde (zivile Luftfahrt) oder 10-12 pro Betriebsstunde (Eisenbahn). Doch bedeutet dies keineswegs, dass die Software diese Güte erreichen kann und muss. Die verlangten geringen Fehlerwahrscheinlichkeiten erreichen die Hersteller meist erst durch in Hardware implementierte risikominimierende Maßnahmen (z. B. Redundanz).
5. Verringern der Fehlerwahrscheinlichkeiten bei Software
Die wirksamste Möglichkeit, eine Software mit wenigen Fehlern zu entwickeln, besteht darin, Fehler konsequent zu vermeiden – und nicht (nur) zu versuchen, diese Fehler beim Testen zu finden und dann zu beseitigen. Deshalb fokussiert die IEC 61508-3 genau darauf: Sie gibt an, welche Maßnahmen Hersteller ergreifen müssen, um ein festgelegtes Safety Level zu erreichen.
Lesen Sie hier mehr über die Aspekte der konstruktiven Qualitätssicherung.
Letztlich haben die Hersteller die Pflicht, die Wahrscheinlichkeit der Schäden zu minimieren. Die Verringerung der Wahrscheinlichkeit der Softwarefehler ist nur eine Möglichkeit. Die IEC 62304 verlangt sogar risikominimierende Maßnahmen außerhalb der Software, um die Software-Sicherheitsklasse reduzieren zu dürfen.
6. Argumentationshilfen
Manche Auditoren und „Technical File Reviewer“ klammern sich noch an den Satz in der (alten) IEC 62304, der die Fehlerwahrscheinlichkeit auf 100 % festlegt. Vielleicht helfen Ihnen bei der Argumentation folgende Überlegungen:
- Dass die Fehlerwahrscheinlichkeit 100 % beträgt, ist dadurch widerlegt, dass Sie einen Test durchführen, der zu den spezifizierten Ergebnissen führt. Die Annahme in der „alten“ IEC 62304 ist damit widerlegt.
- Die „alte“ IEC 62304 stellt nicht mehr den Stand der Technik dar. Diesen repräsentiert (eher) die IEC 62304:2015.
- Die unsägliche 100%-Aussage traf bereits die alte Norm im Kontext der Sicherheitsklassifizierung. Es ging darum, dass man bei dieser Klassifizierung keine Wahrscheinlichkeiten diskutiert. Genau das stellt die neue IEC 62304 klar, und das ist auch sinnvoll.
- Die ISO 14971 erlaubt und verlangt sogar, Wahrscheinlichkeiten zu bestimmen. Anders lassen sich Risiken nicht quantifizieren und bewerten.
- Da die Wahrscheinlichkeitsklassen der Risikoakzeptanzmatrix meist zwei Größenordnungen umfassen, ist es nicht notwendig, die Wahrscheinlichkeit von Softwarefehlern auf 10 % genau abzuschätzen.
- Die wohl wichtigste Norm für sicherheitskritische Systeme, die IEC 61508-3, schreibt vor, wie man Software professionell entwickelt. Und daran haben Sie sich (hoffentlich) gemäß Ihrem „Safety Level“ orientiert.
7. Fazit
Der beste Schutz vor Softwarefehlern besteht in der konstruktiven Qualitätssicherung und in Maßnahmen, die außerhalb des Software-Systems implementiert sind. Beides sollten Sie primär anstreben.
Bei Standalone-Software funktioniert der Ansatz „externe Maßnahmen“ allerdings nicht. Aber auch hier können Sie zumindest die Größenordnung von Fehlerwahrscheinlichkeiten abschätzen.
Wie diese Abschätzung gelingen kann und wie Sie Zielwerte bestimmen und erreichen, hat dieser Beitrag skizziert.
Das Johner Institut unterstützt Medizinproduktehersteller bei der FDA- und IEC-62304-konformen Erstellung von Software-Akten.
Melden Sie sich, wenn das Team Ihnen mit Templates sowie durch das Prüfen, Verbessern und Erstellen der Dokumente dabei helfen kann, dass Sie Ihre Produkte schnell entwickeln sowie sicher durch Zulassungen und Audits geführt werden.
Änderungshistorie
- 2023-04-03: Artikel aktualisiert und viele redaktionelle Änderungen eingefügt
- 2020-06-10: Erste Version des Artikels



Hallo Herr Johner,
wenn man Ihren Artikel liest und von außen auf die Medizintechnik schaut, dann ist schwer zu verstehen, warum so stark auf Fehlerraten etc. fokusiert wird und so wenig auf die inzwischen gut erprobten Maßnahmen wie man gute Software entwickelt. Alle anderen Industrien haben auch das Problem, dass man für Software keine sinnvollen Ausfallraten angeben kann, und trotzdem hat man sehr gute/sichere Wege gefunden um Software mit höchster Qualität und entsprechend niedriger Fehlerraten entwickeln kann. Warum forder die Medizintechnik nicht auch viel konsequenter die Einhaltung der Maßnahmen wie Sie z.B. in der IEC61508-3 definiert sind.
Die Messung der Code Coverage ist eine Maßnahme, aber inzwischen sind auch die Grenzen dieser Methode sehr gut bekannt. Mit die größte Fehlerquelle für Fehler in der Software sind fehlerhafte Spezifikationen. Luftfahrt und Automobilbranche verwenden daher viel Energie diese Fehler zu minimieren und die Methoden zur Erstellung von Spezifikationen zu verbessern, bzw. neue Methoden zu finden.
Ich freue mich auf einen gemeinsamen Austausch.
Viele Grüße
Martin Heininger
Sehr geehrter Herr Heininger,
danke für Ihre Kritik! Sie beklagen, dass ich zu sehr den Fokus auf Fehlerraten legen würde. Ich kann das absolut nachvollziehen.
Gestatten Sie einige Gedanken:
Fazit: Ich vermute, dass wir keinen Dissens haben.
Besten Dank für Ihre wichtige Kritik, die es ermöglicht, die Bedeutung des Testens und die Bestimmung der Fehlerrate im Kontext zu betrachten.
Viele Grüße, Christian Johner
Sehr geehrter Herr Prof. Johner,
sehr geehrter Herr Rosenzweig,
in Ihrer „Faustregel zur Beruhigung“ nennen Sie eine Fehlerwahrscheinlichkeit der Software von ≤ 10-2 pro Anwendungsfall bei Umsetzung der Vorgaben der Normen. Wie kommen Sie auf diese Zahl? Sind dies reine Erfahrungswerte oder basiert dies auf weiterer Literatur?
Mit Dank im Voraus und vielen Grüßen
Niklas Jacobs
Lieber Herr Jacobs,
wir haben einen Beitrag mit Zahlen veröffentlicht, die eine Beziehung zum Testen und den Wahrscheinlichkeiten haben:
https://www.johner-institut.de/blog/iec-62304-medizinische-software/kombinatorische-testen-nicht-nur-bei-software/
Wenn die Wahrscheinlichkeit für einen Softwarefehler größer 10^-2 wäre, dann würden die Fehler beim Testen auffallen.
Herzliche Grüße
Christian Rosenzweig