
Immer mehr Hersteller setzen Machine Learning Libraries wie scikit-learn, TensorFlow und Keras in ihren Produkten ein. Damit beschleunigen sie ihre Forschungs- und Entwicklungsvorhaben.
Allerdings ist nicht allen Herstellern klar, welche regulatorischen Anforderungen sie bei Machine Learning Libraries nachweisen müssen und wie sie das am besten tun. Das führt dazu, dass sie unnötige Aufwände treiben oder bei Audits und Zulassungen in unerwartete Schwierigkeiten geraten. Das verzögert die Produktzulassun
Dieser Beitrag hilft Herstellern und Auditoren zu verstehen, auf was sie bei der Validierung von Machine Learning Libraries achten sollten. Er zeigt zudem, welche Anforderungen (z.B. von Behörden und Benannten Stellen) jeglicher juristischen und logischen Grundlage entbehren.
Erfahren Sie, wie Sie auf Augenhöhe diskutieren, unnötige und unberechtigte Anforderungen und damit Aufwände vermeiden und so Ihr Produkt problemlos auf den Markt bringen können.
Hinweis zur Autorenschaft: Prof. Dr. Oliver Haase ist Mitautor dieses Artikels. Er ist Leiter des Seminars „Künstliche Intelligenz bei Medizinprodukten“ und unterstützt die Kunden des Johner Instituts bei der Validierung von Machine Learning Libraries.
1. Machine Learning Libraries: Eine kurze Einführung
Machine Learning Libraries stellen Herstellern einen großen Teil der Funktionalität bereit, um Verfahren des Machine Learnings bzw. der künstlichen Intelligenz in ihre Produkten zu integrieren.
Zu diesen Verfahren zählen Neuronale Netzwerke, die Regression (z.B. logistische Regression), Tree Ensembles (z.B. Random Forest, XGBoost) und Support Vector Machines.
Hersteller nutzen diese Verfahren, um Daten (z.B. Bilder, Texte, tabellarische Daten) zu klassifizieren (z.B. entscheiden, ob auf einem Bild ein Melanom zu sehen ist oder nicht) oder vorherzusagen (z.B. die beste Medikamentendosis).
Lesen Sie hier mehr zur Anwendung der künstlichen Intelligenz in der Medizin.
Die Libraries dienen nicht nur der Entwicklung und Anwendung von Machine Learning; sie helfen auch bei der Datenaufbereitung und Datenanalyse.
Die Machine Libraries stammen v.a. aus dem universitären Umfeld. Inzwischen werden sie von den Libraries der Tech-Giganten wie Google und Facebook verdrängt. Von diesen stammen z.B. Tensorflow bzw. PyTorch.

2. Regulatorische Anforderungen an Machine Learning Libraries
Zu den wichtigsten regulatorischen Anforderungen, die Hersteller, Benannte Stellen und Behörden im Kontext des Machine Learnings beachten sollten, zählen:
- MDR/IVDR: Anforderungen u.a. an
- die Wiederholbarkeit, Zuverlässigkeit, Robustheit, nachgewiesene Leistungsfähigkeit des Produkts
- Software-Lebenszyklusprozesse, Risikomanagement usw.
- IEC 62304: Anforderungen u.a. an
- die Planung und Dokumentation der Entwicklung,
- die Verifizierung von Code und Dokumenten
- den Einsatz von SOUP-Komponenten
- ISO 13485: Anforderungen u.a. an
- die Kompetenz des Entwicklungsteams und
- die Validierung von computerisierten Systemen, Prozessen und Werkzeugen
In den USA gelten vergleichbare Anforderungen. Die FDA spricht nicht von SOUP, sondern von OTS. Beide Begriffe sind nicht ganz deckungsgleich.
Die US-Behörde hat ein „Proposed Regulatory Framework for Modifications to Artificial Intelligence/Machine Learning (AI/ML)-Based Software as a Medical Device (SaMD)“ veröffentlicht, das für den konkreten Kontext aber nur bedingt relevant ist.
3. Machine Learning Libraries in der Produktentwicklung
Die Hersteller verwenden Machine Learning Libraries in allen Phasen der Forschung, Entwicklung und Anwendung des Produkts: vom Sammeln und Pre-Processing der Daten über das Trainieren des Modells bis zum Verwenden dieses Modell im ausgelieferten Produkt.

Aus regulatorischer Sicht lassen sich diese Phasen in zwei Bereiche unterteilen.
a) Entwicklung und Training des Modells
Der erste Teil dient dazu, das Modell zu entwickeln, d.h. das richtige Verfahren auszuwählen und die Hyperparameter bestmöglich zu wählen.
Wenn der Code für diese Datenvorverarbeitung und das Training des Modells nicht Teil des Medizinprodukts wird (das ist üblicherweise der Fall), ist die IEC 62304 nicht anwendbar. Das gilt sowohl für die Entwicklung dieses Codes als auch für den Einsatz bestehender Machine Learning Libraries (SOUP).
Hingegen müssen die Hersteller die Anforderungen der ISO 13485 z.B. an die Computerized Systems Validation beachten. Darunter fällt die Validierung der Machine Learning Libraries.
Das Ziel der Validierung einer Machine Learning Library besteht nicht (!) darin nachzuweisen, dass das Modell später im Feld korrekte Vorhersagen macht.
Die Validierung der Machine Learning Library muss weder beweisen, dass das Modell das geeignetste ist, noch, dass der Hersteller die besten Hyperparameter gewählt hat.
Vielmehr geht es bei diesem Schritt um den Nachweis, dass die Library für das gewählte Modell, für die vorgegebenen Hyperparameter und für die genutzten Trainingsdaten die besten Parameter „gefittet“ hat.
Beispielsweise muss der Hersteller bei einer logistischen Regression zeigen können, dass die Matrix mit den Gewichten und der Vektor der Achsenabschnitte („intercept vector“) valide für die gegebenen Trainingsdaten sind.
Bitte beachten sie in diesem Kontext den Beitrag zur Computerized Systems Validation.
b) Anwendung des Models
Das trainierte Modell wird nun zusammen mit der Machine Learning Library (oder einem Teil derer) Bestandteil eines (Medizin-)Produkts. Diese Komponente ist dafür verantwortlich, korrekte Vorhersagen zu machen, beispielsweise Bilder richtig zu klassifizieren.
Diese Komponente ist eine SOUP. Deshalb muss der Hersteller die entsprechenden Anforderungen der IEC 62304 an SOUPs nachweisen. Dazu zählt die Pflicht, die Anforderungen an die SOUP zu spezifizieren und verifizieren.
Die IEC 62304 nennt dies zu Recht die Verifizierung der SOUP (bzw. Komponente), auch wenn bei Libraries meist von Validierung gesprochen wird.
Diese Verifizierung bzw. Validierung besteht in dem Nachweis, dass die Komponente die richtige Vorhersage bezüglich des trainierten Modells macht.
Bei dieser Validierung der Machine Learning Library geht es nicht um den Nachweis, dass das Modell korrekte Vorhersagen im Vergleich mit der „ground truth“ macht.
Daher sollten Hersteller die Komponente nicht prüfen, ob die Komponente für korrekt „gelabelte“ Testdaten das erwartete Ergebnis liefert.
Vielmehr sollten sie prüfen, ob das konkrete Modell (z.B. die logistische Regression mit ihren Parametern) für jeden Vektor bei gültigen Inputdaten auch zum mathematisch zu erwartenden Output führt.
4. Validierung von Machine Learning Libraries: Best Practices
a) Vorüberlegungen
Eine Machine Learning Library stellt wie jede Komponente gekapselte Funktionalität über wohldefinierte Schnittstellen zur Verfügung.
Die Besonderheit von Machine Learning Libraries besteht darin, dass der größte Teil dieser Funktionalität und der Schnittstellen beim Trainieren und Optimieren des Modells verwendet wird; nur ein kleiner Teil dagegen während der Laufzeit des Produkts. Oft ist das nur eine einzige Methode, z.B. predict().
Wie oben dargestellt, gelten für das Training und die Anwendung des Models unterschiedliche regulatorische Anforderungen. Hersteller sollten sich diese technische und regulatorische Aufteilung zunutze machen. Dazu können sie die Validierung von Machine-Learning-Bibliotheken in mehrere unabhängige Aufgabenblöcke aufteilen:
- Datenaufbereitung (Anwendungsbereich der ISO 13485)
- Training des Modells (Anwendungsbereich der ISO 13485)
- Anwendung des Modells (Anwendungsbereich der IEC 62304)
Je nach Anwendungsfall existieren noch weitere Softwareanwendungen bzw. -komponenten (z.B. für das Labeling der Daten). Dies würde den Rahmen dieses Artikels jedoch sprengen.
b) Validierung der Datenaufbereitung
Zu den typischen Tätigkeiten der Datenaufbereitung zählen beispielsweise:
- Behandlung ungültiger Daten
- Behandlung fehlender Daten
- Umwandlung von Formaten
- Umwandlung von kontinuierlichen Werten in diskrete
- Normalisierung von Daten
Diese Datenverarbeitungsschritte lassen sich am schnellsten und einfachsten über „normale Tests“ prüfen. Diese Tests sollten als Code implementiert werden, um als Regressionstests dauerhaft zur Verfügung zu stehen.
Die Testorakel lassen sich beispielsweise mit „Nebenrechnungen“ (z.B. in Excel) ableiten.
Als Testmethoden sollten die üblichen Blackbox-Testmethoden wie äquivalenzklassen-, grenzwert- oder fehlerbasiertes Testen zum Einsatz kommen. Das Testen eines „Happy-Path“ ist nicht ausreichend.
Um diese Testmethoden korrekt anwenden zu können, empfiehlt sich eine deskriptive Statistik, um ein genaueres Verständnis der Daten zu erlangen.
c) Validierung des Trainings des Modells
Wie in Abschnitt 3a) ausgeführt, muss der Hersteller bei diesem Schritt nachweisen, dass die Library für das gewählte Modell, für die vorgegebenen Hyperparameter und für die genutzten Trainingsdaten die besten Parameter „gefittet“ hat.
Insbesondere bei einfachen Modellen gelingt dieser Nachweis durch eine grafische Darstellung der tatsächlichen und der gefitteten Werte. Bei komplexeren Modellen bedarf es oft Projektionen in niedrigere Dimensionen.
Fehlermetriken (z.B. r2, p) helfen, die Güte des Modells für die gegebenen Trainingsdaten zu quantifizieren. Zwar können die Machine Learning Libraries diese Metriken bestimmen; aber streng genommen müsste dazu die korrekte Berechnung der Metriken zuvor validiert werden. Allerdings läuft man spätestens dann Gefahr, sinnlose Aufwände zu betreiben, die das Attribut „risk based“ nicht mehr verdienen.
Hersteller dürfen nicht der Versuchung erliegen, durch eine Minimierung dieser Fehler ein Overfitting zu betreiben. Dieses würde die Leistungsfähigkeit des Modells „im Feld“ verringern.
d) Validierung der Anwendung des Modells
Die Funktionen der Machine-Learning-Bibliotheken, die im Medizinprodukt genutzt werden, müssen die Hersteller konform der IEC 62304 spezifizieren und verifizieren bzw. validieren. Dazu sollten sie wie folgt vorgehen:
- Anforderungen an die Funktionen festlegen. Das dürfte in der Regel eine Methode (predict) sein, die für ein gegebenes Modell die korrekten Werte berechnet.
- Voraussetzungen für den Einsatz der Machine Learning Library spezifizieren. Das sind meist Programmiersprachen und Hardwarevoraussetzungen.
- Die Machine Learning Library auswählen (inklusive genauer Version), die die Anforderungen und Voraussetzungen erfüllt
- Die Anomalien dieser Libraries recherchieren und deren Akzeptanz bewerten
- Verifizieren bzw. validieren, dass die Bibliothek – genauer gesagt die entsprechende Funktion(en) – die spezifizierten Anforderungen erfüllen
Ein Auditor kann die Dokumentation all dieser Schritte einfordern. Der letzte Schritt dürfte – zwar nicht bei der Dokumentation, aber bei der Durchführung – der anspruchsvollste sein:
Bereits ein Input-Vektor aus 30 Features, von denen jedes nur noch sieben Werte annehmen kann, würde bereits zu 2,3 x 1025 Werten führen. Das lässt sich unmöglich testen.
Übrigens: Die Reduktion auf sieben Werte ließe sich durch das Bilden von Äquivalenzklassen erreichen.
Um die kombinatorische Explosion zu beherrschen, kommen die Ansätze des Testens von Subsets, z.B. des paarweisen Testens, zum Einsatz. Je mehr Parameter in Kombination getestet werden, desto höher ist die Wahrscheinlichkeit, Fehler zu finden (s. Abb. 3).
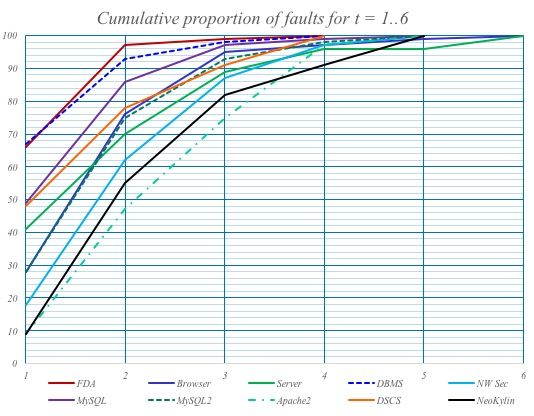
Um diese Tests durchzuführen, benötigt man nicht nur Test-Code, sondern auch Software, um die Testdaten zu generieren.
Das Johner Institut hat diesen Code bereits entwickelt und einige Bibliotheken validiert. Nehmen Sie einfach Kontakt auf, wenn Sie Unterstützung bei der Validierung Ihrer Machine Learning Libraries wünschen.
5. Exkurs: Analogie zum „Model Driven Software Development“
Die europäischen Medizinprodukteregularien adressieren die künstliche Intelligenz und das Machine Learning nicht explizit. Daher ist es hilfreich, Analogien mit bewährten Technologien und Ansätzen zu untersuchen. Dazu zählt das „Model Driven Software Development“.
a) Kurze Einführung in das „Model Driven Software Development“ (MDSD)
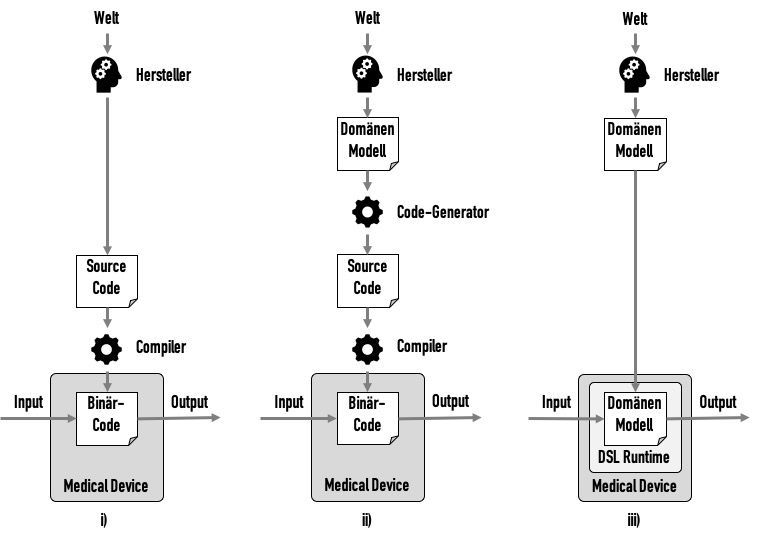
i) Klassische Entwicklung
In der klassischen Softwareentwicklung versucht ein Hersteller, ein Verständnis einer Domäne zu erhalten, sich ein Modell dieser Domäne zu erarbeiten und dieses in Code umzusetzen (s. Abb. 4.i).
Beispielsweise kann ein Modell aussagen, dass ein Patient ein Mensch ist, der über eine oder mehrere Krankheiten verfügt. Im Code gäbe es dann eine Klasse „Patient“, die eine Collection von Klassen „Krankheit“ referenziert.
Diesen Quellcode würde ein Compiler in Binärcode überführen, der dann Teil des Medizinprodukts würde.
Auf die Validierung dieses Compilers kann man auf Basis von Risikoüberlegungen meist verzichten, z.B. weil der Compiler sehr bewährt ist und damit Fehler unwahrscheinlich sind oder weil Fehler beim Compile-Vorgang mit ausreichender Häufigkeit bemerkt würden.
ii) Model Driven Software Development 1
Im nächsten Schritt könnte man zuerst ein Domänen-Modell in einer Domain Specific Language (DSL) erstellen. Ein Code-Generator würde dieses automatisiert in Quellcode überführen. Dieser Code-Generator wäre ein computerisiertes System, das konform mit der ISO 13485 zu validieren ist (s. Abb. 4.ii).
iii) Model Driven Software Development 2
Die nächste Evolutionsstufe besteht darin, den Zwischenschritt der Code-Generierung zu überspringen. Anstatt dessen käme eine „Runtime“ für das Modell zur Anwendung. Das Modell würde direkt im Medizinprodukt ausgeführt (s. Abb. 4.iii).
Diese DSL-Runtime wäre ein Softwarekomponente, die wie jede Softwarekomponente zu spezifizieren und zu verifizieren ist. Ob der Hersteller diese Komponente selbst entwickelt oder eine SOUP verwendet, ist dabei sekundär.
b) Vergleich mit dem Machine Learning
Beim Machine Learning finden sich vergleichbare Ansätze:
- Auch hier werden Artefakte automatisch generiert, nämlich Modelle, die später in einem Produkt zum Einsatz kommen. Und auch hier gibt es eine Runtime für das Modell.
- Sowohl die Modellgenerierung als auch die Runtime erfolgen mit Hilfe von Bibliotheken, den Machine Learning Libraries.
- In gewisser Weise entwickeln auch die Data Scientists ein Programm, ein Domänen-Modell, auf einer höheren Abstraktionsebene.
- Genauso wie der Code-Generator muss auch der Modell-Generator nach ISO 13485 validiert werden. Und genauso wie die DSL-Runtime muss auch der Einsatz der Modell-Runtime den Anforderungen der IEC 62304 genügen.
In dieser Episode bespricht Professor Haase mit Professor Johner die regulatorischen Anforderungen und konkrete Strategien für die Validierung von ML Libraries.
Diese und weitere Podcast-Episoden finden Sie auch hier.

6. Fazit und Zusammenfassung
a) Bitte die Bibliotheken verwenden
Hersteller, die Verfahren der künstlichen Intelligenz wie des Machine Learnings in ihren Produkten einsetzen wollen, sollten bestehende Bibliotheken verwenden. Das hat mehrere Gründe:
- Sie sparen Zeit. In die Entwicklung dieser Machine Learning Libraries dürften viele Personen-Jahrzehnte an Arbeit geflossen sein.
- Sie erhöhen die Qualität: Die Libraries werden vielfach verwendet. Anwender weltweit melden Fehler und helfen damit, diese rasch zu beheben. Bug-Listen verschaffen eine gute Transparenz.
b) Fachwissen gewährleisen
Der Einsatz der Machine Learning Libraries erfordert technisches und regulatorisches Fachwissen. Dieses Fachwissen fordern die ISO 13485 und die MDR ein. Es scheint aber nicht immer gewährleistet zu sein.
Beispielsweise ist die Behauptung mancher Auditoren, dass die SOUP-/OTS-Anforderungen zu erfüllen seien, falsch. Eine Ausnahme bildet die predict-Funktion.
Auch zeugt die Aussage, der Hersteller müsse bei der Validierung von Machine Learning Libraries die Korrektheit des Modells nachweisen, von Unverständnis.
Die Validierung der Bibliotheken muss und kann unabhängig von der Validierung des Produkts erfolgen. Die Zielsetzungen unterscheiden sich grundlegend.
c) Risikobasiert agieren
Die Hersteller müssen die Anforderungen studieren und präzise befolgen. Die Validierung von Software, auch von Machine Learning Libraries, sollte aber risikobasiert erfolgen. Die Wahrscheinlichkeit eines Fehlers im eigenen Code ist meist um Größenordnungen höher als in einer erprobten Bibliothek.
Es steht auch nirgends geschrieben, dass die Bibliothek in Gänze zu validieren ist. Die Regularien fordern, dass die tatsächlich genutzten Anforderungen überprüft werden müssen. Sie stellen meist nur eine kleine Untermenge der Gesamtfunktionalität dar.
Risikobasiertes Arbeiten bedeutet auch, das Produkt und die Bibliothek (SOUP / OTS) im Markt kontinuierlich zu überwachen.
d) Das Rad nicht neu erfinden
So wie es nützlich ist, vorhandene Bibliotheken wiederzuverwenden, ist es hilfreich, auf vorhandene Validierungen von Machine Learning Libraries und deren Überwachung im Markt zuzugreifen.
Man muss auch dieses Rad nicht neu erfinden. Kontaktieren Sie uns, wenn Sie unsere Arbeit wiederverwenden wollen.


