
Müssen Medizinproduktehersteller eine KI wie ChatGPT validieren, die sie bei der Entwicklung, Produktion, Zulassung und Überwachung ihrer Produkte einsetzen?
Falls ja, wie soll das gelingen mit Modellen, die nichtdeterministische Ergebnisse liefern?
Antworten darauf und auf die Frage, was Ihre Auditoren erwarten (sollten), gibt dieser Fachartikel.
- Medizinprodukte- und IVD-Hersteller müssen darauf vorbereitet sein, dass ihre Auditoren die Validierung der GPTs ansprechen.
- In vielen Fällen gibt es die regulatorische Pflicht, Tools wie ChatGPT zu validieren. Das ist insbesondere dann der Fall, wenn diese bei Prozessen im QM-System eingesetzt werden.
- Diese Validierung ist möglich, unterscheidet sich aber in einigen Punkten von der Validierung konventioneller computerisierter Systeme.
- Hersteller sollten den Aufwand für die Validierung der GPTs risikobasiert begrenzen.
- GPTs bzw. LLMs wegen CSV-Pflicht nicht einzusetzen, gefährdet die Wettbewerbsfähigkeit.
1. Einsatz von GPTs bei Medizinprodukte-Herstellern
Bei immer mehr Tätigkeiten greifen Medizinprodukte- und IVD-Hersteller auf GPTs zu, um ihre Produktivität, Innovation und manchmal sogar Konformität zu verbessern.
- Brainstorming für neue Produktideen
- Prüfen der Zweckbestimmung auf Vollständigkeit und Konsistenz
- Extraktion von Anforderungen aus Dokumenten (z. B. Gesetze, Produktbeschreibungen)
- Erstellen einer System-Architektur
- Schreiben von Quell-Code
- Recherchieren und Bewerten klinischer Fachliteratur
- Bewerten von Kundenrückmeldungen
- Ausformulieren von Testberichten
Manche dieser Tätigkeiten führen die Mitarbeitenden nur einmal oder selten durch. Andere, wie die Bewertung von Kundenrückmeldungen, stehen dagegen regelmäßig an.
2. Regulatorische Anforderungen an die Validierung
Um Ärger bei Audits und Inspektionen zu vermeiden, sollten die Hersteller die regulatorischen Vorgaben kennen und erfüllen.
2.1 AI Act
Die Nutzung von LLMs bzw. GPTs fällt unter den Anwendungsbereich des AI Act. Denn MP-Hersteller, die LLMs/GPTs in dieser Art intern nutzen, zählen als „Deployer“ dieser Systeme, auch wenn sie diese überhaupt nicht selbst betreiben.
In der Regel zählen diese Systeme nicht als high-risk, weshalb außer der Pflicht, die KI-Kompetenz („AI Literacy“) nachzuweisen, keine weiteren Anforderungen bestehen. Insbesondere verpflichtet der AI Act nicht zur Validierung.
Beachten Sie die Fachartikel AI Act und zu den weiteren Pflichten von Medizinprodukte- bzw. IVD-Herstellern als Deployer. Ein weiterer Artikel beleuchtet die regulatorischen Anforderungen an Medizinprodukte bzw. IVD, die Verfahren des maschinellen Lernens verwenden.
2.2 ISO 13485
Die ISO 13485 verlangt auch die Kompetenznachweise, sogar spezifisch für jedes Entwicklungsprojekt. Das ist jedoch nicht der Schwerpunkt dieses Artikels; hier geht es vorrangig um die Pflicht zur Validierung.
In Kapitel 4.1.6 fordert die ISO 13485, alle computerisierten Systeme zu validieren, welche im Rahmen des QM-Systems eingesetzt werden. Das ist beispielsweise bei allen oben genannten Anwendungsfällen der Fall.
Analoge, teilweise sogar buchstabenidentische Anforderungen stellt die ISO 13485 an die Infrastruktur (Kapitel 6.3) und an die Validierung der Prozesse einschließlich der dabei eingesetzten Software (Kapitel 7.5.6).
2.3 Weitere regulatorische Anforderungen
Die FDA formuliert in ihren Quality System Regulations (21 CFR part 820) ähnliche Anforderungen. Allerdings stellt die Behörde ihr System auf die Quality System Management Regulations und damit auf die ISO 13485 um.
Beachten Sie die Fachartikel zu den Quality System Management Regulations (QMSR).
In Korea und weiteren Ländern ist die Konformität mit der Norm ISO 42001 verpflichtend, welche auch die Qualitätssicherung KI-basierter Systeme thematisiert.
Beachten Sie den Fachartikel zur ISO 42001 und deren Anforderungen.
3. LLMs als computerisierte Systeme
Sind LLM-basierte GPTs computerisierte Systeme im Sinne der ISO 13485?
Die kurze Antwort lautet: ja.
Die ausführlichere Antwort ist, dass LLM-basierte Systeme als computerisierte Systeme zählen. Falls Hersteller diese Systeme im Rahmen eines oder mehrerer QM-Prozesse einsetzen, fallen diese Systeme unter die Forderungen der ISO 13485.
“The organization shall document procedures for the validation of the application of computer software used in the quality management system.”
Allerdings sind nicht die LLMs zu validieren, also die Modelle selbst, sondern das computerisierte System. Das besteht aus mehr als „nur“ dem LLM (s. Abb. 1), das meist von einem der großen Hersteller wie OpenAI (ChatGPT), Google (Gemini, SORA), Microsoft (Copilot) oder Anthropic (Claude) stammt.
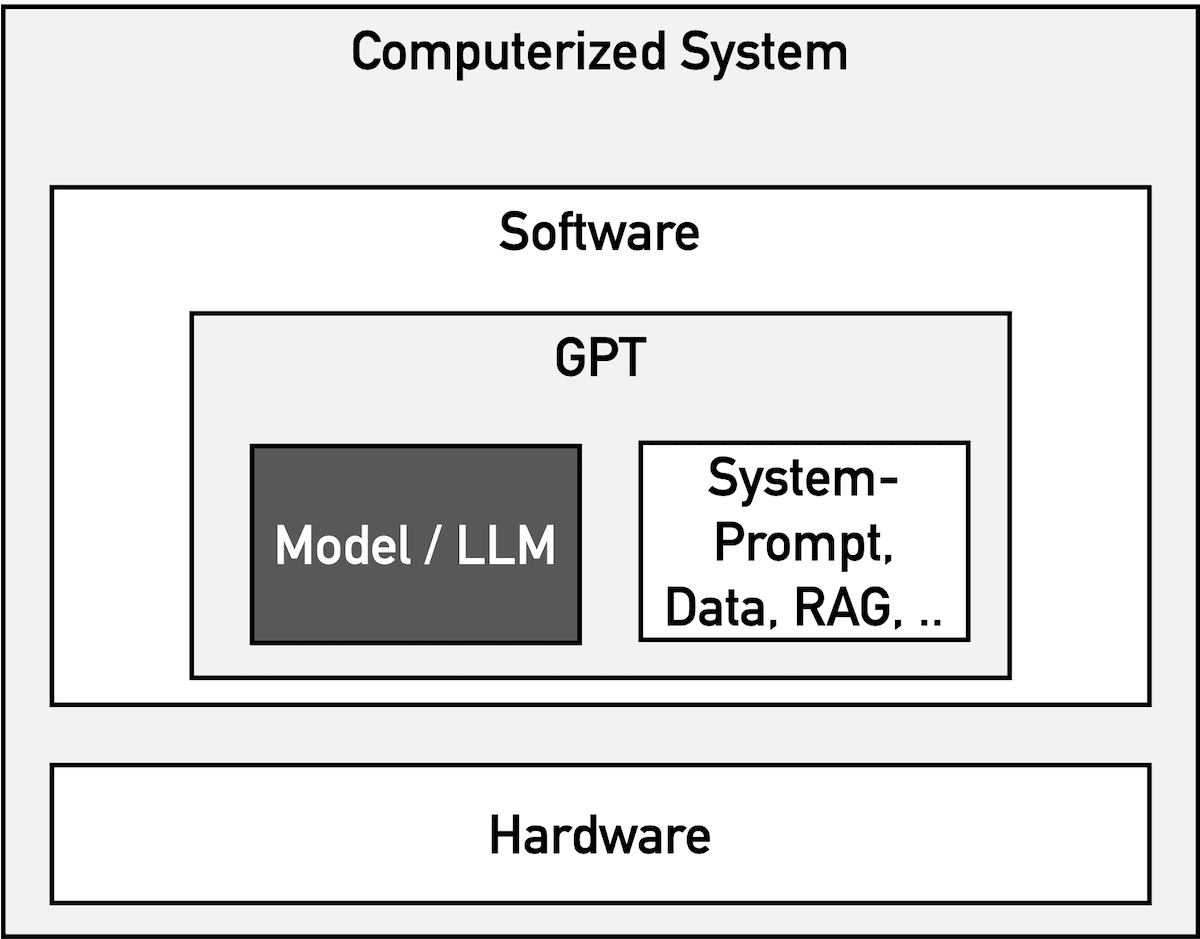
Es ist unerheblich, ob ein System beim Anbieter (z. B. OpenAI) oder beim Medizinprodukte- oder IVD-Hersteller selbst betrieben wird. Entscheidend ist, dass der Hersteller es unter seinem QM-Dach nutzt.
4. Validierungspflicht von GPTs
Hersteller müssen ihre KI, z. B. ihr ChatGPT, validieren, falls die in Abb. 2 genannten Bedingungen erfüllt sind. Die folgenden Teilkapitel erläutern die einzelnen Schritte.
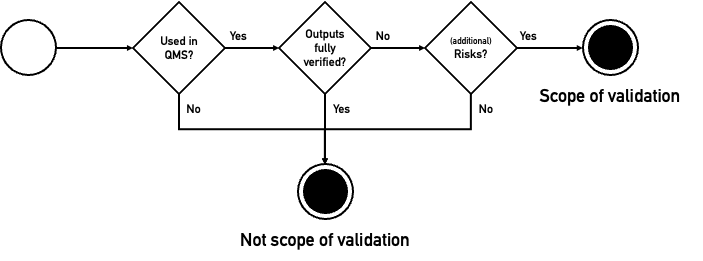
4.1 Entscheidungskriterien
4.1.1 Ja, falls im Rahmen des QM-Systems
Die ISO 13485 verpflichtet im Kapitel 4.1.2 die Organisationen dazu, im Rahmen ihres QM-Systems die Prozesse zu beschreiben. Das sind zumindest die Prozesse, die die Norm selbst vorgibt, beispielsweise:
- Entwicklung einschließlich Verifizierung und Validierung der Produkte
- Erheben der regulatorischen und kundenbezogenen Anforderungen
- Produktion
- Dienstleistungserbringung
- „Marktüberwachung“ (Post-Market Surveillance)
- Umgang mit Kundenrückmeldungen
- Kommunikation mit Behörden einschließlich Vigilanz
Alle in Abschnitt 1 genannten und von LLMs unterstützten Tätigkeiten fallen in den Anwendungsbereich des eigenen QM-Systems!
Für LLMs, die bei ausgelagerten Prozessen verwendet werden, gelten die gleichen regulatorischen Anforderungen und damit auch die Pflicht zu deren Validierung.
4.1.2 Nein, falls die Ergebnisse vollständig geprüft werden
Die ISO 13485 beschreibt in Abschnitt 4.1.6 keine Ausnahme von der Validierungspflicht für computerisierte Systeme. Dennoch lässt sich solch eine Ausnahme herleiten, falls die Ergebnisse des computerisierten Systems im Anschluss vollständig geprüft werden.
Diese Argumentation stützt sich auf folgende Gedanken:
- Die sehr vergleichbaren Anforderungen an die Tool- bzw. Prozessvalidierung muss der Hersteller nicht erfüllen, falls gilt: „output [is] verified by subsequent monitoring or measurement and, as a consequence, deficiencies become apparent“.
- Die gleiche Sichtweise formuliert die FDA im 21 CFR part 820.75 a).
- Die Erlaubnis, risikobasiert vorzugehen, bedeutet, dass ohne Risiko auch keine Validierung notwendig ist.
Ein „subsequent monitoring or measurement“ kann erfolgen durch
- eine manuelle Überprüfung,
- automatisierte Tests (z. B. Software) oder
- nachfolgende Prozessschritte, die fehlerhafte Outputs des GPTs zwangsläufig offenbaren (etwa weil ein Bauteil nicht montiert werden kann).
4.1.3 Nein, falls keine (zusätzlichen) Risiken durch fehlerhafte Outputs des LLMs entstehen
Der vorangegangenen Überlegung folgend, müssen Hersteller ihr LLM nicht validieren, falls kein (zusätzliches) Risiko besteht. In diesem Zusammenhang verbergen sich hinter dem Wort „Risiko“ zwei verschiedene Arten von Risiken:
- Risiken für Patienten, Anwender und Dritte im Sinne der ISO 14971 (streng genommen betrachtet die Norm auch die Umwelt und Güter)
- Risiken für die Konformität des eigenen Unternehmens und der eigenen Produkte
Ein lesenswerter Fachartikel von Dr. Sebastian Raschka beschreibt, wie die LLMs validiert werden können.
4.2 Beispiele
4.2.1 Beispiele für nicht validierungspflichtige GPT-basierte Systeme
| Beispiel | Begründung |
| Brainstorming von Produktideen | Es ist unerheblich, ob Ideen von Menschen oder LLMs stammen. In jedem Fall werden Menschen diese Ideen prüfen und wahlweise verwerfen oder weiternutzen. |
| UI-Entwurf | Ein UI-Entwurf lässt sich i.d.R. nicht automatisch übernehmen. Daher werden in der Praxis Menschen diesen Entwurf bewerten und anpassen, bevor er umgesetzt und im Rahmen der formativen und summativen Evaluation bewertet wird. Auch hier ist es unerheblich, ob initiale UI-Entwürfe von Menschen oder LLMs stammen. |
| Generieren von Software-Code (aber nicht Test-Code) | Software-Code ist nie fehlerfrei. Genau deshalb sollte er besonders intensiv geprüft werden, z. B. durch den Compiler, Reviews, Software-Tests, statische Code-Analysen sowie bei anschließenden Prüfschritten wie Integrationstests. Falls LLM-generierter Code genau diesen Qualitätssicherungsmaßnahmen unterzogen wird, sind die Risiken auf dasselbe Maß minimiert wie bei von Menschen geschriebenem Code. Das gilt insbesondere für „Boiler-Plate-Code“. Üblicherweise lassen Hersteller den Code für kritische Algorithmen nicht generieren. Andernfalls wäre eine Validierung des GPTs zu empfehlen. |
| Generieren von SOPs | SOPs müssen geprüft und freigegeben werden. Das gilt auch für generierte SOPs. Somit wird das Endergebnis vollständig von Menschen verifiziert. |
Die Beispiele in Tabelle 1 gehen davon aus, dass die Menschen ihrer Aufgabe tatsächlich nachkommen und die Ergebnisse prüfen. Das ist bei selten eingesetzten LLMs häufiger der Fall als bei LLMs im Routinebetrieb. Entwickler, die es gewohnt sind, dass ihr LLM hochwertigen Code generiert, neigen eher dazu, diesen Code nicht mehr genau zu prüfen.
Hersteller können diesem automatisierten Abnicken („Automation Bias“) entgegenwirken, z. B. indem sie das Thema in den AI-Literacy-Schulungen ins Bewusstsein rücken und konkrete Review-Ergebnisse einfordern.
4.2.2 Beispiele für Grenzfälle
| Beispiel | Begründung |
| Schreiben einer Software-Architektur (analog System-Architektur, Isolationsdiagramm, Spannungsversorgungskonzept) | Entwurfsdokumente unterlaufen viele weitere explizite und implizite Prüfschritte: Es finden Dokumenten-Reviews statt. Das Entwicklungsteam liest und prüft implizit das Dokument beim Umsetzen (z. B. auf Vollständigkeit, Korrektheit, Umsetzbarkeit). Die Entwicklungsergebnisse durchlaufen viele weitere Prüfschritte. Damit ist nicht gesagt, dass ein vom LLM verursachter Fehler grundsätzlich entdeckt wird und Risiken ausgeschlossen sind; aber die Risiken sollten bei einem guten/bewährten Prompt niedriger sein als bei einem manuell erstellten Entwurfsdokument. Die Qualität des Prompts (bzw. der Prompt Chain oder des kompletten GPTs) könnte über Reviews gesichert werden. Fazit: Ein Verzicht auf die Validierung des GPTs müsste begründet sein. |
| Schreiben von Test-Code | Test-Code wird fast nie durch weitere Software-Tests auf Korrektheit und Vollständigkeit getestet. Allerdings wird auch der Test-Code durch den Compiler geprüft, er durchläuft (idealerweise) ein Code-Review und wird durch die Coverage-Bestimmung zumindest indirekt geprüft. Damit hängt die Validierungspflicht von der Art und Intensität nachfolgender Prüfschritte sowie von der Kritikalität der getesteten Software ab. |
4.2.3 Beispiele für validierungspflichtige GPT-basierte Systeme
| Beispiel | Begründung |
| Schreiben eines Prüfplans | Fehler in Prüfplänen können beispielsweise in Form von falschen Grenzwerten oder fehlenden Prüfkriterien bzw. fehlenden Testfällen bestehen. Solche Fehler lassen sich zum einen schwerer finden als in Entwurfsdokumenten, schließlich führt eine Lücke im Testplan zu einem nicht ausreichend getesteten Testobjekt (z. B. Produkt). Zum anderen ist die Gefahr höher, dass die Suche nach diesen Fehlern (z. B. bei Reviews) durch Zeitdruck am Projektende und abnehmende Motivation beeinträchtigt ist. Die Natur der LLMs kann zu Fehlern führen, welche Menschen nicht unterlaufen würden. Insofern greift eine Argumentation mit dem Verweis auf den Stand der Technik (Mensch) nicht. |
| Ermitteln regulatorischer Anforderungen | Das korrekte Ermitteln der regulatorischen Anforderungen ist entscheidend für die Konformität des Produkts bzw. Unternehmens. Daher führen Fehler zu nennenswerten (regulatorischen) Risiken. Menschen neigen im Gegensatz zu GPTs nicht dazu, Anforderungen zu erfinden, komplett zu verfälschen oder zu ignorieren. Das erhöht die Risiken von LLMs auch relativ zu den Risiken bei manueller Ermittlung. |
| Auswerten der klinischen Fachliteratur | Analoge Überlegungen gelten für LLMs, die klinische Fachliteratur suchen, nach Inhalten durchsuchen oder bewerten. Klinische Bewertungen mit durch LLMs erfundenen Literaturquellen haben bereits den Weg zu Benannten Stellen gefunden. Solche nicht validierten LLMs torpedieren den Nutzen und die Relevanz der klinischen Bewertung. |
| Bewerten von Kundenrückmeldungen | Fehler bei der Bewertung von Kundenrückmeldungen würden dazu führen, dass kritische Rückmeldungen unentdeckt bleiben und die notwendigen Maßnahmen nicht eingeleitet werden. Das kann Patienten gefährden. |
4.3. Fazit
Hersteller sollten mehrere Kriterien betrachten, wenn sie über die Validierungspflicht entscheiden.
Das sind neben den in Kapitel 4.1 genannten auch die folgenden:
4.3.1 Nachfolgende Prozessschritte
Je schlechter nachfolgende Prozessschritte mögliche Fehler eines vorausgegangenen Schritts aufdecken können, desto wichtiger ist die Güte des vorausgegangenen Prozessschritts. Daher sollten Hersteller Tools wie ChatGPT stärker validieren, wenn diese auf der rechten Seite des V-Modells zum Einsatz kommen.
4.3.2 Häufigkeit und Art des Einsatzes
Eine Validierung erscheint auch als besonders notwendig, wenn ein Werkzeug wie ein GPT routinemäßig eingesetzt wird, etwa zum Bewerten von Kundenrückmeldungen.
Hingegen wird eine Person, die ein Spezialwerkzeug für einen einmaligen Einsatz entwickelt, um ein konkretes Problem zu lösen, das Ergebnis dieses Werkzeugs mit hoher Wahrscheinlichkeit vollständig prüfen.
5. GPT-Validierungspraxis
5.1 Allgemeine CSV-Best-Practices beachten
Die gesetzlichen und normativen Vorgaben wie die ISO 13485 unterscheiden nicht, ob ein computerisiertes System LLMs verwendet oder nicht. Daher sind alle Best Practices für die CSV auch für GPTs anwendbar.
Beachten Sie unseren Fachartikel zur Computerized Systems Validation. Dieser referenziert weitere Richtlinien und Normen wie die IEC 80002-2.
5.2 Spezifisches Risikomanagement betreiben
Allerdings unterscheidet sich die Validierung KI-basierter computerisierter Systeme, insbesondere von Systemen, die generative KI verwenden, von der Validierung von Systemen, die keine KI verwenden. Das betrifft unter anderem das Risikomanagement, was wegen des risk-based approach bei der Validierung besonders relevant ist.
5.2.1 Spezifische Risiken
KI-basierte Systeme weisen spezifische Risiken auf, die verschiedene Ursachen haben können:
- Die Technologien und Modelle unterliegen ständigen Änderungen.
- Die Ergebnisse sind selten 100 % korrekt und vollständig.
- Den GPTs unterlaufen Fehler, die Menschen nicht machen würden.
- Die LLMs (die Modelle als Kernel des GPTs) sind nur schwer validierbar.
- Viele GPTs können auch für Zwecke eingesetzt werden, für die sie nicht vorgesehen waren und validiert wurden.
Die Risiken hängen stark von den Inputs und deren Variabilität ab. Beispielsweise sind die Risiken eines GPTs, das jeden Prompt entgegennimmt, schwerer abzuschätzen als jene für ein GPT, das nur strukturierte Daten in einem festgelegten Format und mit definierter Semantik entgegennimmt (z. B. Werte nur aus Klassifikation).
Dieser Beitrag adressiert nicht KI-basierte Medizinprodukte und IVD. Beachten Sie dazu unseren Übersichtsartikel sowie den Artikel zu den regulatorischen Anforderungen an das Machine Learning.
5.2.2 Spezifische Maßnahmen
Auch die Maßnahmen unterscheiden sich:
- Human-in-the-Loop
- Architektur des Systems (z. B. Parallelisierung mit anschließendem Voting durch mehrere LLMs oder Limitierung des LLMs auf die Rolle als „Conversational UI“)
- Auswertung der „Protocols“ (wie vom AI Act für High-Risk-Systeme gefordert)
- Wahl der Modellparameter, etwa Temperatur und Top-K (z. B. um Reproduzierbarkeit zu erhöhen)
- Einsatz strukturierter Daten im Context Window
5.2.3 Spezifische Kriterien für die Risikoakzeptanz
Vorbemerkung
Insbesondere deutsche Gesetzgeber, Behörden und Benannte Stellen tendieren zu dem Glauben, dass mehr Verbote und strengere Auslegung der gesetzlichen Vorgaben zu einer erhöhten Patientensicherheit führen. Dabei provoziert diese Haltung wiederum Risiken durch fehlende, nicht bezahlbare und nicht ausreichend innovative/wirksame Medizinprodukte.
Daher sollten Hersteller bei der Risikobewertung auch mit dem Nutzen durch die KI argumentieren können. Ohne Nutzen sind keine Risiken akzeptabel.
Stand der Technik
Zudem sollte ein Unternehmen die Risiken nicht absolut bewerten, sondern am Stand der Technik bemessen. Diesen Stand der Technik bilden:
- Menschen
- Systeme ohne KI
- KI-basierte Systeme, welche die KI anders einsetzen (andere Modelle, Architekturen …)
Der Stand der Technik beim Bewerten der klinischen Fachliteratur ist der Mensch, konkret medizinisch-wissenschaftliche Expertinnen und Experten.
Der Stand der Technik bei der statistischen Auswertung von Produktionsfehlern oder Kundenrückmeldungen sind klassische Software-Anwendungen (ohne KI).
Daher sind Fehler, die beim aktuellen Stand der Technik nicht entstehen würden (z. B. erfundene Gesetzestexte oder wissenschaftliche Quellen), aber bei Chat-Bots entstehen, nicht akzeptabel.
Hingegen ist eine übersehene Kundenbeschwerde bzw. eine fehlerhaft klassifizierte Kundenrückmeldung kein Ausschlusskriterium für den Einsatz eines LLMs. Denn solche Fehler unterlaufen auch Menschen.
Hersteller sollten die Anforderungen (beispielsweise in Form von Qualitätsmetriken) auch aus dem Stand der Technik und damit risikobasiert ableiten – und prüfen.
5.3 Weitere spezifische Best Practices beachten
5.3.1 Festlegen, was das GPT ist
Hersteller müssen Klarheit darüber haben, was das zu validierende System und was der Input dieses Systems ist. Beispielsweise kann ein Prompt ein Input sein, aber im Fall von Custom-GPTs oder System-Prompts auch Teil des zu validierenden Systems.
Wie in Abschnitt 5.2.1 beschrieben, hängen die Risiken stark von den Inputs und deren „Variabilität“ ab.
5.3.2 Ground Truth bestimmen
Ein Hersteller sollte Klarheit darüber haben, welche Ergebnisse richtig sind. Das ist in vielen Fällen schwieriger als gedacht.
Das Johner Institut hat erfahren, dass verschiedene Expertinnen und Experten keine vollständige Einigung darüber erzielen, welche Sätze bzw. Satzfragmente in regulatorischen Dokumenten Anforderungen formulieren und welche „nur“ als Erläuterung, Begründung oder Beispiel dienen.
Genauso klassifizieren selbst Personen Kundenrückmeldungen unterschiedlich, wenn man sie ihnen mehrfach vorlegt.
Auch bei der Frage, welches Element in einer Ursachenkette eine Gefährdung, eine Gefährdungsklasse (z. B. elektrische Energie), eine Gefährdungsursache oder ein „Root Cause“ ist, führt reproduzierbar zu unterschiedlichen Antworten.
Daher ist es unumgänglich, dass ausreichend viele Datensätze bereitstehen,
- die dem LLM als Beispiele zur Verfügung gestellt werden (→ n-shot-prompting) und
- mit denen die Leistungsfähigkeit des GPTs bewertet werden kann.
Bei einem GPT zur Bewertung von Kundenrückmeldungen ist es hilfreich, mehrere Hundert Kundenrückmeldungen zu „labeln“. Dazu müsste man Datensätze sowohl von mehreren Personen als auch mehrfach von einer Person bewerten lassen.
Damit können Hersteller
- die intrapersonelle und interpersonelle Varianz bestimmen (und daraus die Metriken ableiten) sowie
- Beispiele für eindeutig kritische und eindeutig unkritische Kundenrückmeldungen sowie strittige Rückmeldungen zusammenstellen.
5.3.3 Metriken bestimmen
Erst wenn diese Beispiele vorliegen, ist es sinnvoll, die Qualitätsmetriken zu bestimmen. Die Wahl dieser Metriken hängt stark von der Zweckbestimmung des GPTs ab.
Bei einem GPT, das sicherheitsrelevante Informationen in Kundenrückmeldungen identifiziert, ist die Genauigkeit (Accuracy, Prozentsatz richtig klassifizierter Kundenrückmeldungen) nicht das geeignete Maß. Vielmehr bietet sich hier die Sensitivität an.
5.3.4 Überprüfung nicht auf Metriken beschränken
Abhängig von der Aufgabe sollten sich Hersteller bei der Prüfung nicht auf die Einhaltung der Metriken beschränken. Sie würden damit nur „den Mittelwert“ prüfen. Daher sind andere Messgrößen und Untersuchungen zu empfehlen:
- Bestimmung des „Confidence Intervals“ für jede Metrik
- Untersuchung, wie stark die Leistungsfähigkeit von einzelnen „Features“ abhängt. Dabei können „Partial Dependency Plots“ oder „Feature Important Plots“ hilfreich sein.
- Auch die klassischen Software-Qualitätseigenschaften gemäß ISO 25010 sollten die Hersteller beachten, etwa Robustheit, Performanz und IT-Sicherheit.
Bei einem GPT, das sicherheitsrelevante Informationen in Kundenrückmeldungen identifiziert, könnte solch eine Analyse ergeben, dass die Wahrscheinlichkeit, eine kritische Meldung zu bekommen, vom Krankenhaus, vom Produkt, vom Zeitpunkt (z. B. kurz nach Service) oder von der Sprache oder der Länge der Rückmeldung abhängt.
Davon abhängig würde der Hersteller Informationen über die Sicherheit seines Produkts (z. B. Zeitpunkt) oder Leistungsfähigkeit seines GPTs (z. B. Sprache oder Länge der Rückmeldung) erhalten.
5.3.5 Dokumentenlenkung sicherstellen
Die Lenkung des GPTs stellt eine Voraussetzung für dessen normenkonforme Validierung dar. Diese Lenkung setzt voraus:
- Der Hersteller hat beschrieben, was das GPT und dessen Zweckbestimmung ist (siehe auch 5.3.1).
- Diese Elemente des GPTs (Prompts, RAG-Dokumente, Modell, Modellparameter …) sind unter Versionskontrolle oder zumindest pro Version dokumentiert.
- Änderungen an diesen Elementen werden dokumentiert, geprüft und freigegeben.
Die Validierungsdokumentation unterliegt ebenfalls der Dokumentenlenkung. Das reicht von den Systemanforderungen über die Bewertung/Klassifizierung des Systems und die Prüfpläne bis zu den Testergebnissen und den Testberichten.
Für die Inventarisierung von Systemen und deren Validierungsständen bieten sich Configuration Management Databases (CMDB) an.
6. FAQ
Dieses Kapitel ist Work in Progress. Das Johner Institut ergänzt bei Bedarf weitere Fragen und Antworten.
6.1 Wie geht man damit um, dass Systeme nicht deterministisch sind?
Wie oben ausgeführt, gilt es, den Stand der Technik zu erreichen. Weder bei einem einzelnen bzw. bei mehreren Menschen würde man erwarten:
- Uneingeschränkte Reproduzierbarkeit
- Absolute Vollständigkeit
- Hundertprozentige Korrektheit
Den Grad der menschlichen Reproduzierbarkeit, Vollständigkeit und Korrektheit sollten Hersteller bestimmen und über ihr GPT erreichen; zumindest, wenn der Mensch den Stand der Technik bildet. Andernfalls würden Hersteller die Risiken erhöhen, was gemäß ISO 14971 sowie MDR bzw. IVDR nicht erlaubt ist.
Falls Maschinen (z. B. „klassische Software“) den Stand der Technik bilden, die vollständig reproduzierbar sowie vollständig korrekt arbeiten, wären nichtdeterministische Ergebnisse nicht hinnehmbar.
Diese Aussagen sind aber nur dann relevant, wenn das GPT validierungspflichtig ist.
Über Modellparameter lässt sich ein GPT ausreichend deterministisch gestalten. Das ist aber weder grundsätzlich verlangt noch sinnvoll.
6.2 Wo soll ich starten?
Starten Sie damit, Ihre GPTs zu inventarisieren, beispielsweise anhand der folgenden Attribute:
- Name, ID des Systems
- Zweckbestimmung
- Prozess(e), in denen es zum Einsatz kommt
- Validierungspflicht
- Risiken
- Stand der Technik (nächstbeste Alternative)
Prüfen Sie dann Ihre SOP für die CSV daraufhin, ob sie auch für LLM-basierte Systeme geeignet ist. Bei Bedarf passen Sie sie an.
Anschließend erstellen Sie für das GPT mit dem höchsten Risiko den ersten Validierungsplan.
Falls Sie bei einem der Schritte hängenbleiben oder diese Aufgaben abgeben wollen, dann melden Sie sich bei uns.
7. Fazit und Zusammenfassung
GPTs wie ChatGPT helfen den Herstellern von Medizinprodukten, effizienter und produktiver zu arbeiten und damit ihre Wettbewerbsfähigkeit zu verbessern. Deshalb sollten sie diese neuen technischen Möglichkeiten nutzen.
Allerdings dürfen sie sich nicht im rechtsfreien Raum bewegen. Aussagen wie „Die GPTs lassen sich ohnehin nicht validieren, daher muss ich das nicht tun“ sind ebenso falsch wie irreführend.
GPTs sind validierbar, auch wenn die Validierung einige Besonderheiten aufweist. Davon abgesehen gelten die Best Practices der Computerized Systems Validation.
Hersteller, Behörden und Benannte Stellen sollten die Validierungskirche im Dorf belassen und nichts einfordern, was man von Menschen bzw. konventionellen Systemen nicht auch verlangen würde. Es gibt einen Stand der Technik.
Sie müssen bei vielen Anwendungsfällen ihr ChatGPT validieren. Gehen Sie davon aus, dass Ihre Behörde oder Benannte Stelle das im nächsten Audit thematisiert.
Das Johner Institut unterstützt Hersteller von Medizinprodukten und IVD dabei,
- über die Validierungspflicht der GPTs zu entscheiden,
- Vorgabedokumente wie SOPs, Arbeitsanweisungen und Templates zu erstellen,
- GPTs normen- und gesetzeskonform zu validieren,
- dafür die passenden Methoden, Metriken und Werkzeuge auszuwählen und die GPTs sogar zu verbessern und
- die Aufwände für all das zu minimieren.
Melden Sie sich, unabhängig davon, ob Sie nur Anregungen wünschen oder das Thema komplett abgeben wollen.


Danke, für dieses schönen Artikel. Eine Sache habe ich allerdings nicht verstanden. Warum ist die Erstellung von Prüfplänen kein Grenzfall wie das Schreiben von Testskripten? Fehlende Testfälle sollten in der Traceability auffallen. Falsche Grenzwerte lassen sich leicht – sogar KI-gestützt – im Review finden. Fehlende Prüfkriterien sind tatsächlich wahrscheinlich (LLMs haben einen starken Bias hinsichtlich funktionaler Tests), aber in einem guten QM System habe ich dafür ein Template, denn auch wir Menschen denken spontan nicht sofort an die x-ilities (Portability etc.). Da kommt der Bias ja schließlich her. Bleibt die Behauptung, dass die Motivation für ein gründliches Review nachlässt, die ich ziemlich gewagt finde. Der Prüfplan entsteht erst ganz am Ende? Da läuft doch im Prozess was falsch! Man könnte genauso gut argumentieren, dass die KI auch am Ende der Entwicklung noch motiviert und deshalb besser ist. Oder übersehe ich da was?
Liebe Anne,
danke für Deine wertvollen Gedanken und Deine exzellente Frage!
Ich fürchte, dass das nie ganz trennscharf sein wird, auch wenn ich mein Bestes getan habe, um Kriterien zu finden.
Die Überlegungen waren:
Die meisten Firmen, auf die wir stoßen, erstellen die Prüfpläne erst ziemlich am Ende. Ob das gut ist, ist eine andere Frage. Bei diesen Firmen gibt es oft eine eigene Abteilung („V&V“), die die Prüfpläne abarbeitet, die aus der Entwicklung kommen. Weil das Entwicklungsprojekt wie immer hinter dem Projektplan hängt, muss jetzt V&V die Prüfpläne möglichst „effizient“ abarbeiten. Und damit sind einige Zutaten bereitet, um Fehler in dem Projektplan zu übersehen:
Ob die KI am Ende der Entwicklung motiviert, kann ich nicht beurteilen. Uns wurde so etwas noch nicht kommuniziert.
Wichtig: Es geht mir nicht darum, die Validierungsaufwände zu erhöhen. Im Gegenteil: Ein Ziel dieses Artikels besteht darin, „die Kirche im Dorf zu lassen“. Wenn ein Unternehmen seine Prozesse so etabliert hat, dass Fehler in den Prüfplänen ausreichend wahrscheinlich vermieden oder gefunden werden, dann ist das großartig. Denn dann ist das Risiko niedrig und damit der Validierungsaufwand.
Die Einschätzung resultiert aus vielen, vielen Entwicklungsprojekten, die wir begleitet haben. Und das sind Projekte und eben keine ausreichend präzise geregelten (oder regelbaren?) Prozesse.
Nochmals besten Dank für Deinen Input, der mir hilft, Dinge ausführlicher zu beschreiben.
Beste Grüße, Christian
Sehr geehrter Herr Prof. Johner,
mit großem Interesse habe ich Ihren sehr lesenswerten Artikel zur Validierung von GPTs gelesen.
Wir verwenden das Johner Regulatory Radar zur Unterstützung unserer regulatorischen Pflichten und nutzen auch das Post Market Radar. Soviel ich weiß, sind diese Tools KI-basiert. Können Sie mir sagen, ob diese KI Tools validiert sind?
Beste Grüße
Jörg Laube
tetronik GmbH
Lieber Herr Laube,
vielen Dank für Ihre spannende Frage!
Sie haben völlig Recht, die regulatorischen Pflichten an die Tool-Validierung greifen auch beim Regulatory Radar. Diesen Pflichten unterliegt die nutzende Organisation. Aber der Hersteller kann dabei helfen, wie wir das auch gerne tun. Damit lastet die Arbeit auf mehreren Schultern:
Wie Sie sehen, kann der Hersteller die Organisation, die das Tool nutzt, gar nicht vollständig entlasten.
Noch ein weiterer Gedanke: Die Validierungspflicht gilt völlig unabhängig davon, ob das Tool KI verwendet/enthält oder nicht.
Mit den besten Grüßen
Christian Johner